Week 8 - Memory management
Overview
The operation system supports the abstraction of virtual memory for processes so it need to:
- Map virtual memory onto physical memory.
- Manage what should be in physical memory.
- Validate memory access of processes.
When we speak about memory there are two main abstractions OS can use for memory:
- Paging system: This uses memory pages which fixes the size of the smallest unit that can be moved between memory locations. This is the currently the most popular way to manage memory.
- Memory segmentation: This uses memory segments which have variable sizes.
To support these memory mapping there are 3 bits of hardware that take a virtual address to a place on RAM.
- Memory Management Unit (MMU): A component on the CPU that performs the mapping from virtual memory to physical memory. This is also responsible for raising faults for illegal access or accesses that require different permissions.
- Translation Lookaside Buffer (TLB): A cache within the MMU to speed up address mappings.
- Memory controller: A component that maps different sticks of RAM into one contiguous physical address space to be used by the MMU.
")
Page tables
Page table
Link to originalPage table
A page table maps addresses in the virtual address space of a process which is indexed by the virtual page number and an offset within that page. The virtual page number is mapped to a physical frame number which combined with the offset can identify a location in physical memory. The simplest way to do this is with flat page tables. This is a page table contains one entry for each virtual page number which is the index in the page table. The page table entry then consists of the physical frame number a long with some management bits which inform the operating system if the memory mapping is valid, what permissions the process has for this memory. To then do the mapping it sums the offset from the virtual address with the physical frame number in the page table to get the physical address. Other page table types exist such as Multi-level page tables or Inverted page tables (IPT).
Note here in paging that the physical address consists of a virtual page number with an offset.
Offset index
Physical memory is only allocated to virtual memory when it is first referenced. This is identified by the operating system when a physical memories location is not in a page table. When this happens the operating system takes control and either allocates the memory or swaps something out of RAM to provide space for the new memory. This is called ‘allocation on first touch’. When a page is removed from RAM this is called ‘reclaimed’.
Page table entry
Link to originalPage table entry
A page table entry is indexed by the virtual page number and contains the physical frame number which is how the mapping between the two is carried out. However, the entry also contains some other management fields such as:
- Present: If mapping is still valid or not. As the frame may have been reclaimed.
- Dirty: If the frame has been written too. For example if it represents something on disk we know it still need to be copied down to disk.
- Access: If the frame has been accessed by the process for read or write operations.
- Protection: If the process has read/write/execute permissions on the memory.
Though these differ by architecture. See below for a particular example.
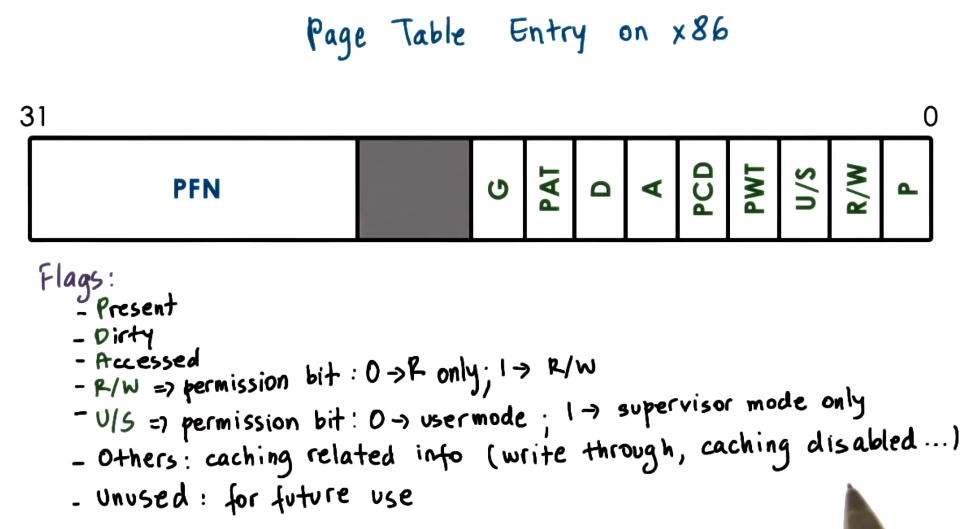
The MMU uses the flags within the page table entry to determine if the processes operation on that memory is valid. If not it raises a fault which triggers the kernels page fault handler.
Page table size
There are two major factors that influence the page table size:
- The register size. I.e. if you are on a 32-bit architecture or a 64-bit architecture.
- The size of the pages. I.e. What size chunks are you cutting your RAM into.
The register size is important as it limits the size of the virtual address. The size of the page is important as it determines how large the offset needs to be.
Page sizes are determined by the operating system but commonly are 4kB, 2MB (large), and 1GB (huge).
")
32-bit architecture with 4kB page size
As a byte is the smallest addressable size, lets use this as our unit for the below calculations. As we have a 32-bit architecture the virtual addresses have size 32 bits. As the page size is 4kB =
B we will need 12 bits for the offset. Therefore we are left with 20 bits of the virtual address for the Virtual page number (VPN). This means there are pages. With this we can now work out the size of the page table. For this architecture, 32-bit addresses are 4 bytes large which is the size of the page table entry. We have page entries so we get B = 4 MB of size.
64-bit architecture with 4kB page size
If we do the same calculation with a 64-bit architecture we get 64-12 = 62 bits for the number of page table entries. Therefore we get a page table size of
B = 64PB per process! Way too large to hold in memory or disk for most computers!
Multi-level page tables
Multi-level page tables
Link to originalMulti-level page tables
To reduce the memory overhead of a single large page table, modern systems use a hierarchical paging structure called a multi-level page table. Instead of a single, flat table mapping all virtual pages to physical frames, the multi-level approach breaks this into a series of smaller nested page tables.
At the top level, an outer page table contains pointers to lower-level page tables, continuing down the hierarchy until reaching the final level (the “inner page table”), which directly maps virtual pages to physical frames.
This approach optimizes memory usage by allocating only the page tables that are needed—a technique known as “on-demand allocation” or “sparse paging”. If a virtual memory region is never accessed, its corresponding page tables are never created, saving memory.
Adding more levels increases granularity, reducing wasted space, but comes at the cost of more memory lookups per access, potentially increasing TLB misses and reducing performance.
")
Single vs double size comparison
Suppose we have the same processes running only a 12-bit architecture. Though we run it on two different machines where:
- the first uses flat page tables, with virtual addresses having a 6 bit VPN and a 6-bit offset, and
- the second uses 2-level page tables, with the virtual addresses having a 2 bit first index and 4 bit second index with a 6-bit offset.
Suppose both of these processes use the first 2kB and last 1kB of memory. How large are the page tables and how many entries do they use?
Notice as they both have 6 bit off sets the page size is
B. Therefore the first 2kB = B takes the first entries and the last 1kB takes the last entries. In the flat table the page table has 64 entries in which 48 are used. In the second example the fist table has 4 entries with only 3 of these being used, the second layer has 16 entries and in all 3 tables all of these are used. You can see in the second example we had in total 52 page table entries with only 1 not used but in the first we had 64 entries with 16 not being used.
Inverted page tables
Inverted page tables (IPT)
Link to originalInverted page tables
Traditional page tables are indexed by virtual addresses, but on 64-bit architectures, the virtual address space can be many petabytes, while physical memory is usually much smaller (gigabytes or terabytes). This results in large page tables, consuming significant memory.
An inverted page table (IPT) solves this by indexing entries by physical page frame rather than by virtual address. Each entry stores the PID and Virtual page number (VPN) to uniquely identify which process and virtual address map to that physical frame.
This causes slow lookups, as searching by virtual address requires a linear search, which is inefficient. Many systems use a hash table to speed up lookups. The Translation Lookaside Buffer (TLB) caches recent translations, avoiding frequent IPT lookups.
Segmentation
Memory segmentation
Link to originalMemory segmentation
Segmentation is a memory management technique that divides memory into logically distinct memory segments, such as code, data, and stack segments, each with a variable size. Instead of using fixed-size blocks like paging, segmentation allows programs to allocate memory dynamically based on their needs. The operating system manages memory through a descriptor table, which stores the base address and limit of each segment. Segmentation can reduce internal fragmentation but may lead to external fragmentation without additional management techniques.
Descriptor table
Link to originalDescriptor table
In segmentation the virtual addresses contain a selector and an offset. The selector relates to some segment descriptor, such as code, data, heap, ect. The descriptor table maps this selector to the segment address in physical memory.
Normally segmentation is used in conjunction with paging. First use segmentation to cut down the virtual memory then using paging to get pages within that segment.
Page size
What is the correct page size? This depends on your application, normally page sizes come in 3 different buckets ‘regular’ about 4kB, ‘large’ about 2MB and ‘huge’ about 1GB.
Larger page sizes means smaller page tables as the offset does more of the work - however this can lead to internal fragmentation. Therefore applications that are likely to need large contiguous blocks of memory such as databases are better off with larger or huge table sizes but applications that to store lots of small objects are better off with smaller page tables.
Memory allocation
Memory allocator
Link to originalMemory allocator
The memory allocator gets used when a process needs map some physical memory onto its virtual memory. There are two different kinds of allocators:
- Kernel-level allocators: That is used by the kernel to get memory for the kernel state but also the static process state.
- User-level allocators: Dynamic process state on the heap obtained by calls to malloc/free.
The main challenge memory allocators suffer from is external fragmentation.
External fragmentation
Link to originalExternal fragmentation
External fragmentation occurs when free memory is split into small, non-contiguous blocks, making it impossible to allocate a large contiguous block despite having enough total free space. This happens in systems that use variable-sized allocations (e.g., segmentation or heap memory management). For example if a program repeatedly allocates and frees different-sized memory chunks, gaps form between allocated blocks, preventing large allocations.
")
The linux kernel has two types of allocators.
Buddy Allocator
Link to originalBuddy Allocator
The buddy allocator is a memory allocator used in the linux kernel to efficiently manage contiguous blocks of memory. It works by dividing memory into blocks of sizes that are powers of 2.
How It Works
- Allocation:
- Memory is initially available as large power-of-2 blocks.
- When a request is made, the allocator finds the smallest block that fits the request.
- If the block is too large, it recursively splits it into two equal “buddies” until the requested size is reached.
- Deallocation & Merging (“Buddy System”)
- When memory is freed, the allocator checks whether its buddy (the adjacent block of the same size) is also free.
- If both buddies are free, they are merged back into a larger block.
- This process continues up the hierarchy, helping to reduce fragmentation.
Advantages & Trade-offs
Fast allocation & deallocation: Simple bitwise operations track buddy pairs.
Merging reduces fragmentation: Helps prevent external fragmentation.
Internal fragmentation → Requests that don’t match a power-of-2 size may waste memory.
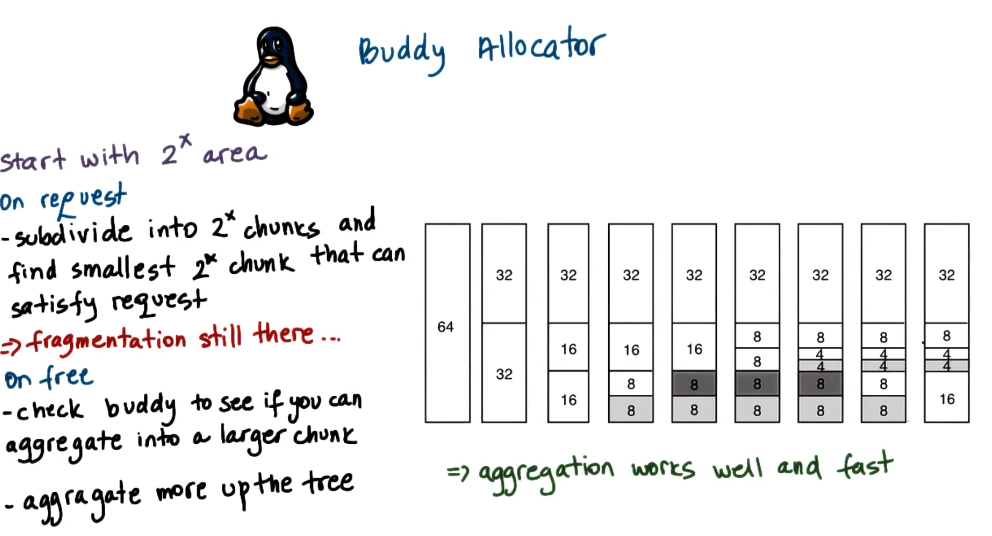
However, the objects the linux kernel normally stores are not powers of 2. Causing a lot of internal fragmentation so another memory allocator is also used.
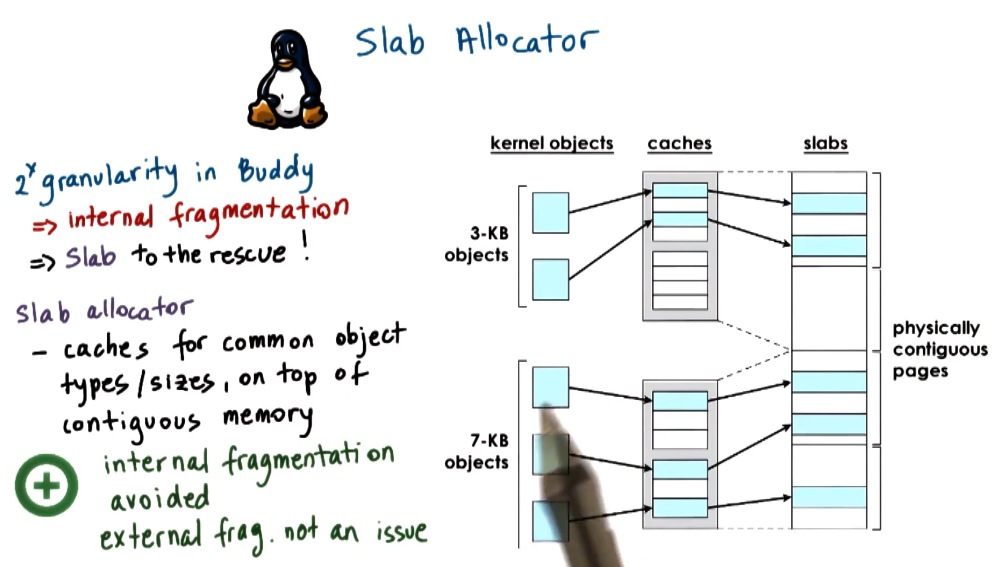
Slab allocator
Link to originalSlab allocator
The slab allocator is a memory allocator used in the linux kernel to efficiently allocate and reuse small, fixed-size objects (e.g., process descriptors, file system inodes).
How It Works
- Preallocation of Objects
- Memory is divided into large contiguous regions called slabs.
- Each slab is further divided into fixed-size chunks, each designed to hold a specific type of kernel object (e.g., task structs, buffers).
- Object Reuse & Caching
- Instead of frequently allocating and freeing memory from the general heap, the slab allocator maintains a cache of preallocated objects.
- When a new object is needed, it is taken from an available slot in a slab, avoiding costly memory allocation operations.
- Memory Efficiency
- Because objects fit exactly into slab slots, there is no internal fragmentation or external fragmentation.
- Slabs can be partially filled, fully allocated, or completely free. Fully free slabs can be released back to the system, reclaiming memory.
Advantages & Trade-offs
Fast allocation & deallocation: Objects are preallocated and reused.
No fragmentation: Objects fit precisely into preallocated slabs.
Efficient for frequently used objects: Great for kernel structures like inodes, task structs, and buffers. Not ideal for variable-sized allocations: Works best when objects are of predictable, uniform sizes.
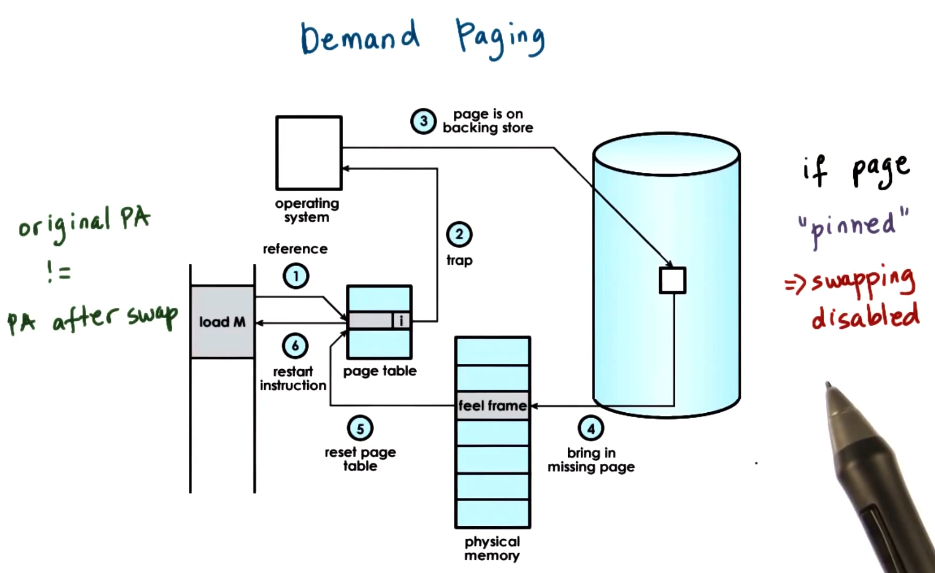
Demand paging
Demand paging
Link to originalDemand paging
As virtual memory is far larger than physical memory to maximize resource usage the operating system will swap out memory in RAM to some secondary storage like the disk. In doing so it updates the page table entry to reflect this. If the memory is then accessed again it needs to pull it back off the secondary storage. It does this in the following way:
- Memory is referenced.
- The MMU raises a trap to hand control to the operating system.
- The page is recovered from the secondary storage.
- The page is copied into a free memory frame in RAM.
- The page table entry is updated to reflect this change.
- Control is handed back to the process.
When should pages be swapped out?
- When we are nearing full use of the memory.
- When the CPU utilization is low.
What pages should be swapped out?
- Pages that aren’t going to be used in the future.
- Hard to tell in practice so we use heuristics.
- History-based predictions such as LRU
- Access bit in the page table entry can be used for this.
- Pages that don’t need to be written out.
- Dirty bit in the page table entry can be used for this.
- Avoid swapping non-swappable pages, such as some kernel state. Applications can ‘pin’ their pages to guarantee they stay in memory.
Copy on write
Copy on write (COW)
Link to originalCopy on write (COW)
If two processes are using the same memory the operating system can let them share access to the same frame. Only needing to copy the data across if a write on the data is initialized by either process. This delays operations from the operating system until they are absolutely necessary.
/../../images/copy_on_write.png)
Checkpointing
Checkpointing
Link to originalCheckpointing
Checkpointing is an operation performed by the operating system where it copies a current processes state and saves a write protected copy of it. The operating system can then resume the process from that state in the future. This is useful for:
- Debugging: You can jump between checkpoints to find out where bugs happen.
- Migration: You can move the processes state onto another machine and resume it from there.
- Disaster recovery: You can save old versions of the program if something goes wrong and restart from a past checkpoint.