Week 6 - Thread Performance Considerations
Additional reading
Choosing a threading model
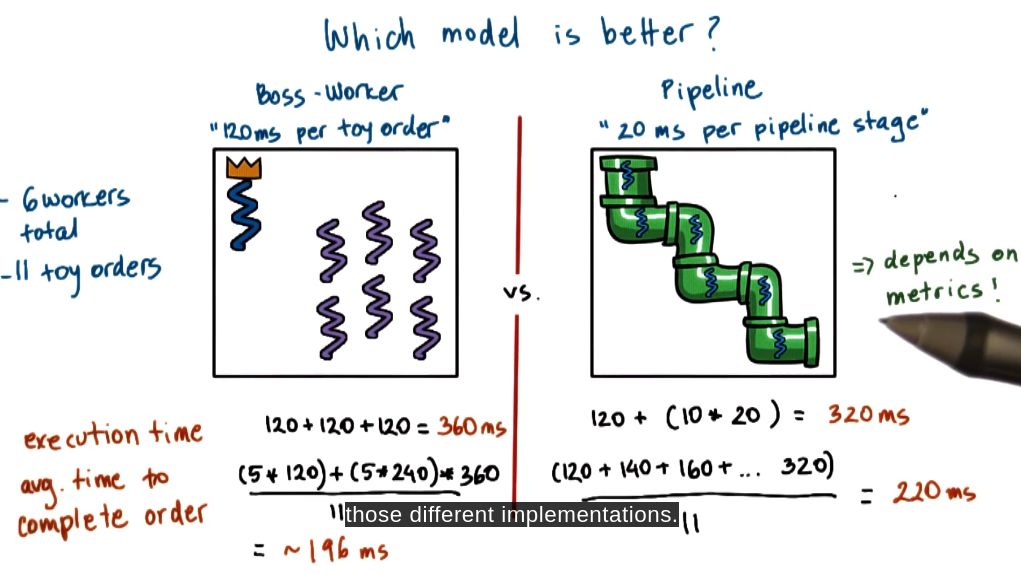
When choosing a model for threading it is important to pick the metric you care about before deciding on implementation. In the example above the server would prefer the pipeline as it is cheaper in terms of CPU time whereas for clients they would prefer the boss-worker model as it reduced average order time completion.
Metric
A metric is a measurement standard. I needs to be a measurable and quantifiable property of the system we are interested in that can be used to evaluate the system behavior.
Some examples are:
- Execution time: The amount of time it takes to complete a job.
- Throughput: The amount of jobs completed per unit of time. This measures the actual work done.
- Request rate: The amount of requests received per unit of time. This represents how many requests the system can accept but not necessarily complete.
- Resource utilization: How much of the CPU time is idling or memory used, ect.
- Wait time: The average amount of time spent waiting to start a request.
- Platform efficiency: How well I can utilize the resources within my platform.
- Performance / currency spent: This is useful when comparing different hardware choices for a data center.
- Performance / Watts: This is useful when considering environmental impacts of your operation.
- Percentage of SLA violations: The amount of requests that violate your service level agreement with your users.
- Client perceived performance: For example with videos human can’t see more than 30 frames per second - therefore maintaining it at that would give a good client perceived performance. More frames per second than that will not increase their perception of performance.
- Aggregate performance: Normally you care about balancing off different factors against one another so taking an average is useful here.
To evaluate impacts of changes on our metrics we build a test bed to see the impact of changes we are making:
- Real experiments with real payload.
- Toy experiments with mocked payload.
- Simulations.

Simple web server comparison
In the rest of this lecture we are comparing different implementations for a web-server to see the pros and cons of each.
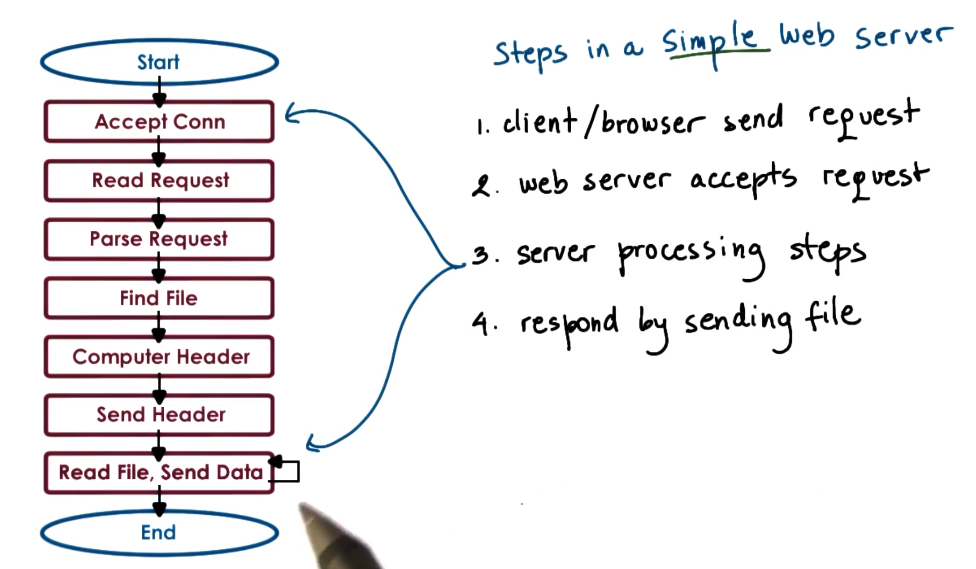
The steps within a file server have different needs - some may be CPU bound such as parsing headers, others may be i/O bound like reading a file.
Multi-processing
We implement this by simply take a working single process single threaded implementation for the webserver. Then spin up multiple processes for this. This has the following payoffs:
- Simple in terms of coding.
- High overheads to context switch.
- High memory usage for different PCB.
- Complicated to make is share resources like a bound port, or file handlers.
Simple multi-threading approach
We implement this similarly to the multi-process approach. With one thread handling the whole request start to finish. This has the following payoffs:
- Cheaper context switching due to shared state and address space.
- Not as simple implementation as it requires synchronization.
- Library will need to support threads (not an issue in modern platforms).
Event driven model
In this model we will use an event-bus to determine what our machine needs to do. This will then switch to the appropriate action associated to that message. Operations will be non-blocking for I/O events. This will be running on a single process with a single thread.
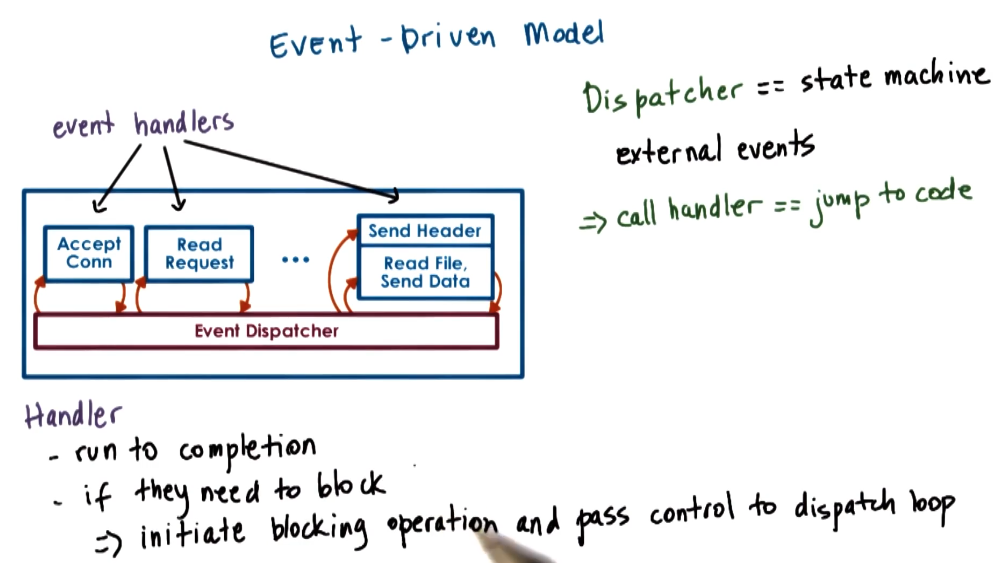
This can be spun out to support multiple CPU’s but it adds complexity to ensure each CPU only gets the correct tasks. However, for this analysis we will not consider this.
This model has some payoffs also:
- More complicated to program as you need to use non-blocking I/O calls using poll or epoll to scan open file descriptors.
- More efficient as you do not waste any time on context switching.
- Smaller memory requirement as there is a single context.
- No synchronization.
Async I/O operations
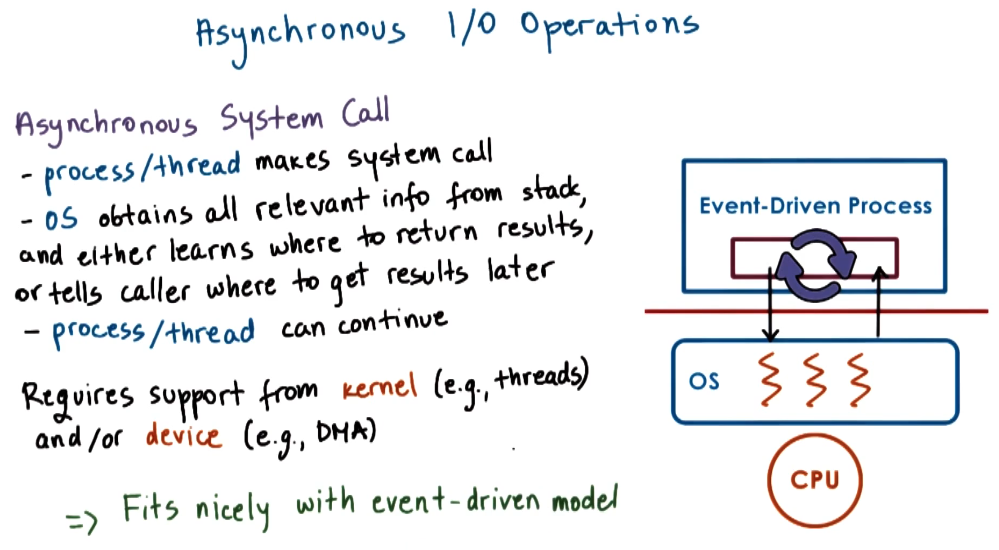
The main drawback of asyncronous I/O operations is the need to poll open file descriptors for responses. To get around this we can use helper-functions that run on a thread that will handle the blocking I/O operations and put an event on the event dispatcher after they have completed.
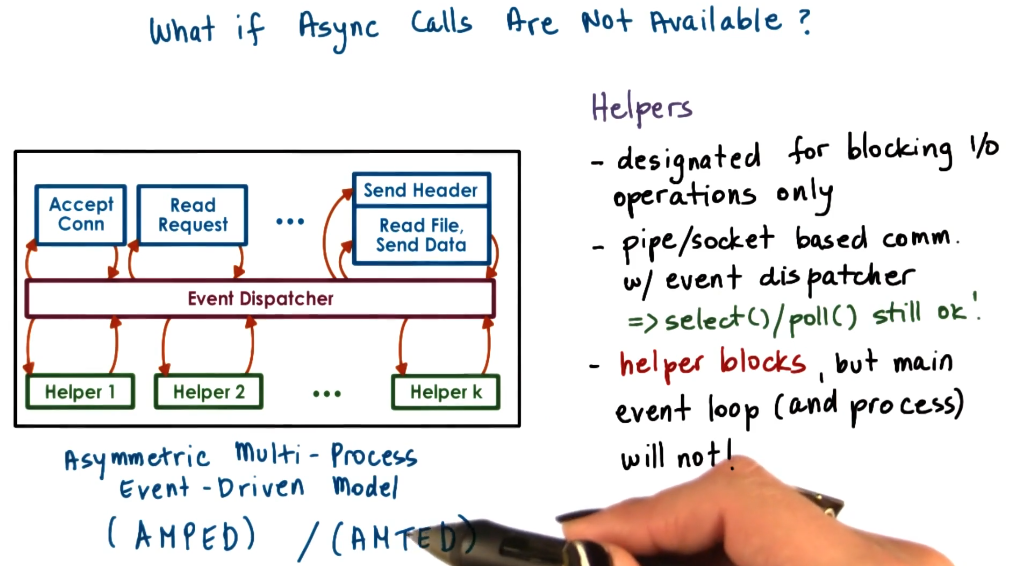
Note: In the paper it suggestions using processes for this - however as discussed before it is faster to use threads.
This has the following payoffs:
- resolves portability limitations of basic event-driven model.
- Smaller footprint than regular worker threads.
- Limited applicability in other services.
- Event routing in multiple CPU systems can be complicated.
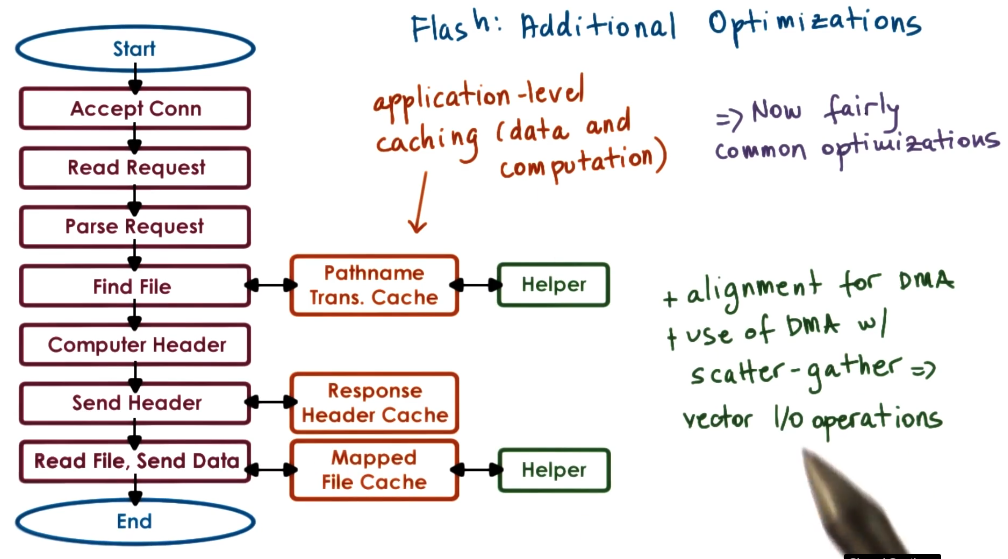
Flash web-server
The flash web-server uses the helpers as laid out above but makes some additional optimizations.
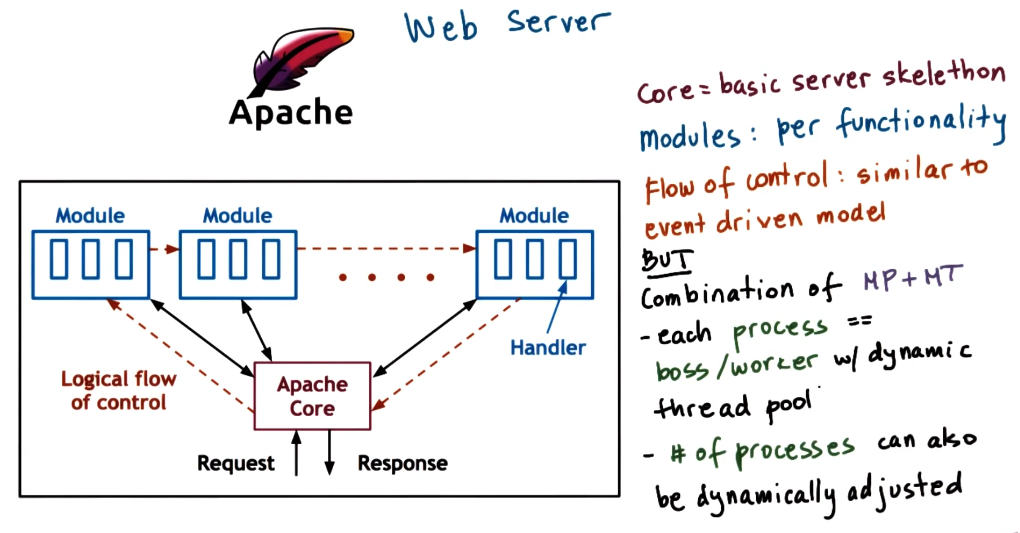
Apache web server
The Apache webserver uses a mix of the boss worker pattern and a pipeline model with modules that can be plugged in.
Comparison
Whenever comparing two systems you need to define:
- What are you comparing? (Only change this)
- What work loads will be used?
- How will you measure performance?
In this comparison they choose:
- They compared different implementations of the web-server (all of these had the flash optimizations around caching of file descriptors headers):
- Multi-process
- Multi-threaded with boss-worker pattern
- Single process even-driven (SPED) model (without helper functions)
- Zeus (similar to SPED but with 2 processes)
- Apache
- Flash
- Workload:
- They used trace-based workloads (i.e. capture real world connections to a webserver and replay it):
- They used one webserver that served files that did not fit in memory.
- Another webserver which was smaller and could easily be cached.
- They also generated synthetic loads.
- They used trace-based workloads (i.e. capture real world connections to a webserver and replay it):
- Metrics:
- Bandwidth, measured in bytes/time
- Connection rate, requests/time
They evaluated these metrics on file size:
- larger file size can be ammortized per connection, so can achieve higher bandwidth.
- Larger file size means more work per connection so lower connection rate.
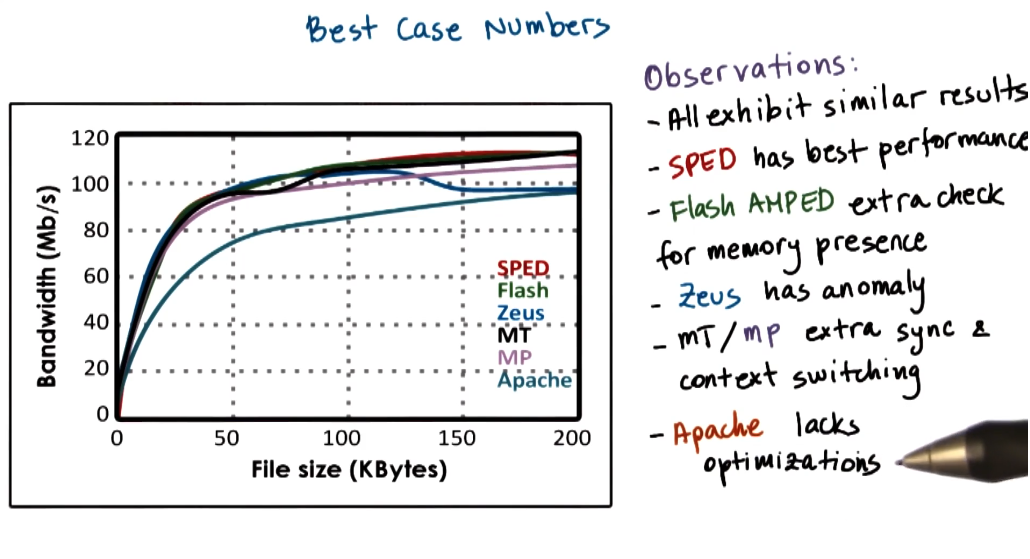
Best case
The best case analysis was lots of connections for the same page. They varied the page size and looked at the performance of different servers.
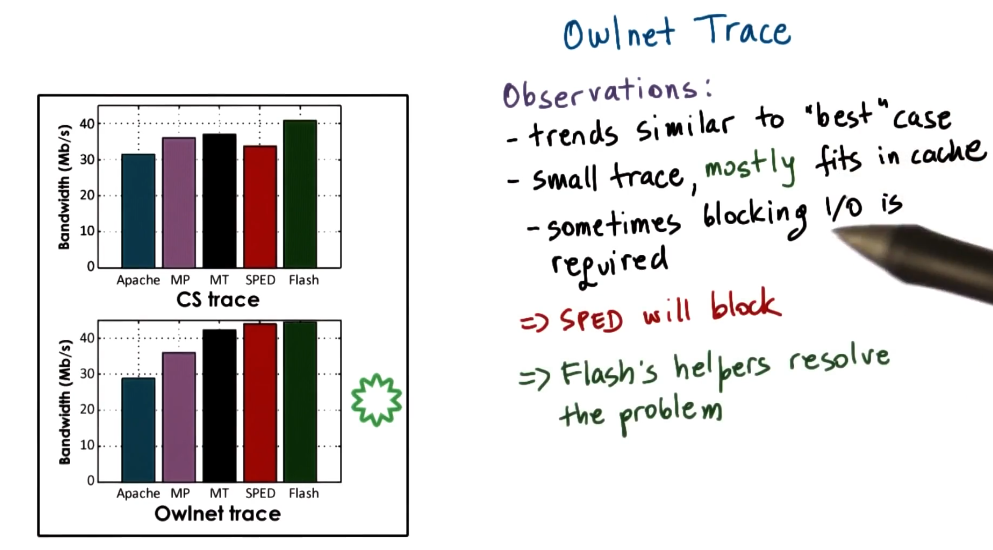
Trace small files
The small file trace (Owlnet) followed a similar pattern to the best case analysis.
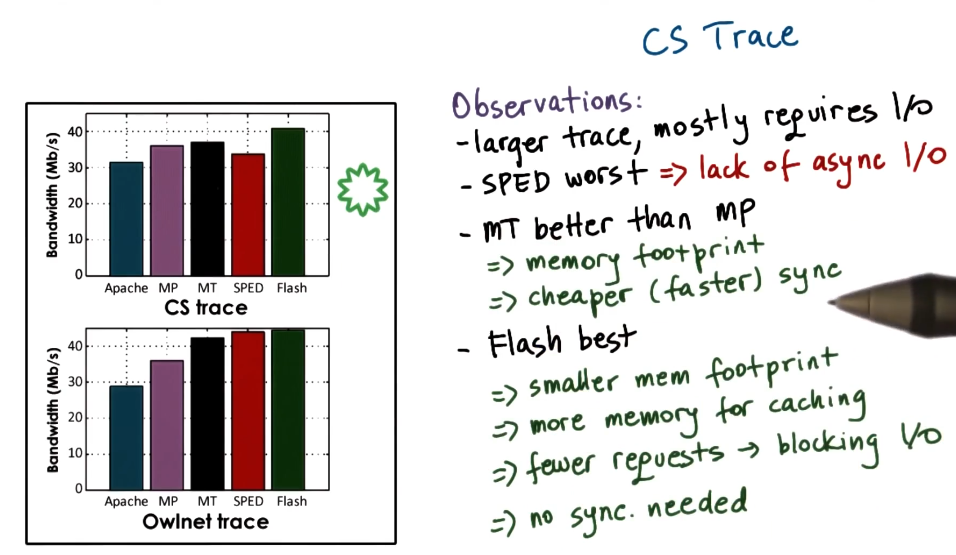
Trace large files
For large files SPED was the worst for the need to do I/O operations which mean time spent polling for non-blocking I/O operations.
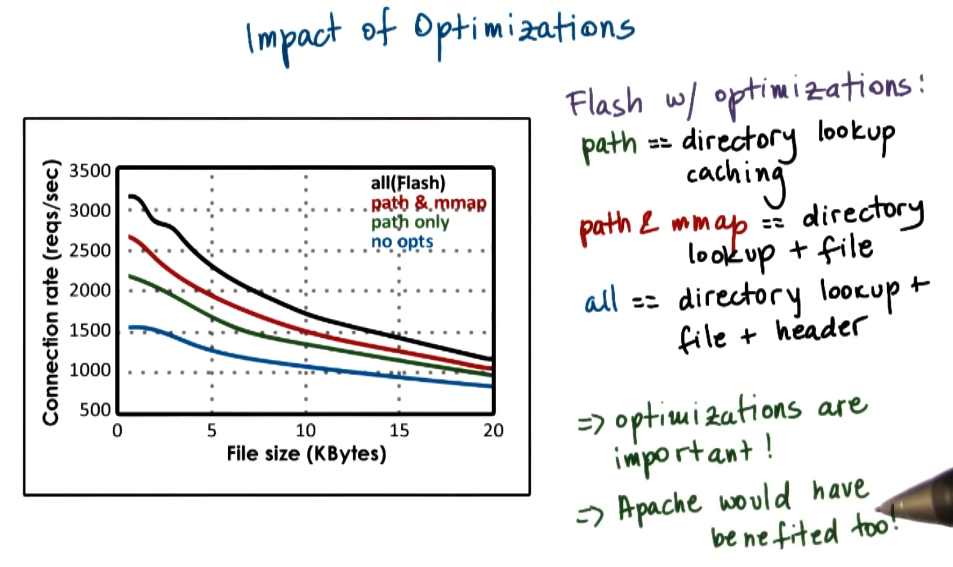
Optimisations
To understand why Apache performed so poorly, it is useful to see the impact of the optimizations the paper suggests.
Summary
- When data is in cache:
- SPED performed better than Flash as there was an unneeded test for memory presence.
- Both SPED and Flash outperformed MT/MP implementations.
- When data was not in cache
- Flash outperformed SPED as there was no blocking I/O operations.
- Flash outperformed MT/MP approach as it was more memory efficient and used less context switching.