Week 3 - Linear-Time Median
Median list problem
Given an unsorted list
of numbers - you want to find the median ( ) element.
Not usual Median definition
This isn’t the usual definition of median, which in the case of odd
would return the mean of the and elements.
Though we can solve a more generic problem.
th smallest element Given an unsorted list
of numbers - you want to find the ‘th smallest element.
Using Merge sort
A basic algorithm would be to use Merge sort on
Using divide and conquer better
We are going to use ideas from quick sort algorithm.
The basic idea is summed up in following pseudocode
Select(A, k):
1. Choose a piviot p.
2. Partition A into A_{<p}, A_{=p}, and A_{>p}.
3. If k <= |A_{<p}| then return Select(A_{<p}, k)
4. If |A_{<p}| < k <= |A_{<p}| + |A_{=p}| then retrun p.
5. Otherwise return Select(A_{>p}, k - (|A_{<p}| + |A_{=p}|))Though we have skipped how we choose a pivot. We need that pivot is close to the median to get a good running time. Lets assume the running time of this algorithm is
Choosing the pivot
We say a pivot is good if
Random pivot
If I choose any random element
Recursive pivot
Instead of finding a median of
Trick
Divide
into sets of 5 and find the median of each of these sets. Call this set . Then find the median of the set .
Let
Which gives
FastSelect(A,k):
1. Break A into ceiling of n/5 groups, G_i with atmost 5 elements in.
2. For i = 1 -> n/5 sort G_i and let m_i = median(G_i)
3. Let S = {m_1, ..., m_{n/5}}
4. Let p = FastSelect(S,n/10)
5. Partition A into A_{<p}, A_{=p}, A_{>p}.
6. Return based on the following conditions.
1. If k <= |A_{<p}| then return FastSelect(A_{<p}, k)
2. If k > |A_{<p}| + |A_{=p}| then return
FastSelect(A_{>p}, k - |A_{<p}| + |A_{=p}|)
3. Else return p.Breaking
Sorting a single
We run this sort on
We then run our algorithm on a subproblem of size
Pivot runtime
So finding this pivot takes
time.
Partitioning the set takes
The last step of the algorithm takes at most
Combining this all together we have
Why is this true?
I don’t know, but this looks like it could be solved using Akra–Bazzi method or Recursion tree method.
Useful discussion about this
Let me see if I can help explain this. I find the best way to solve recurrences with multiple sub-problems is to think in terms of the “recursive tree”.
For the recurrence
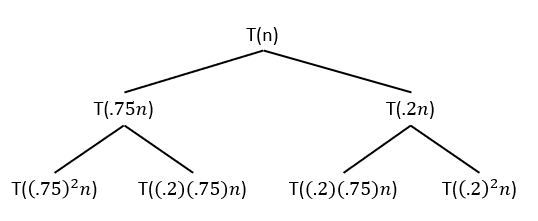
And the work at this second level? Sum up the four leaves, and you get:
Now, what happens with the recurrence
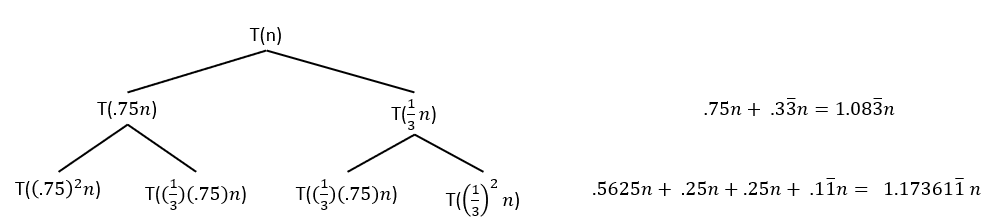
Now we see that at each level the work increases, so we no longer have a linear overall run time. The work at the bottom of the recursive stack will dominate the overall runtime.
What’s the intuition behind this? The overall number of operations at each level is bounded by the total n at that level. As you make successive recursive calls, does n shrink? does it grow? or is it held constant?
Further questions
Change 5 in the analysis
What happens to the run time if we switch out 5 for 3 or 7 in the analysis of this algorithm?
If we use