Week 8 - Security
The Internet was not designed or built with security in mind. Security came as an afterthought after adversaries started misusing or abusing Internet services, resources and infrastructure.
An attack on a system aims to compromise properties of a secure communication.
Additional reading
Important Readings
Measuring and Detecting Fast-Flux Service Networks
https://www.sec.tu-bs.de/pubs/2008-ndss.pdfLinks to an external site.
FIRE: FInding Rogue nEtworks
https://sites.cs.ucsb.edu/~chris/research/doc/acsac09_fire.pdfLinks to an external site.
ASwatch: An AS Reputation System to Expose Bulletproof Hosting ASes
Links to an external site.https://conferences.sigcomm.org/sigcomm/2015/pdf/papers/p625.pdfLinks to an external site.
Cloudy with a Chance of Breach: Forecasting Cyber Security Incident
https://www.usenix.org/system/files/conference/usenixsecurity15/sec15-paper-liu.pdfLinks to an external site.
ARTEMIS: Neutralizing BGP Hijacking Within a Minute
https://www.inspire.edu.gr/wp-content/pdfs/artemis_TON2018.pdfLinks to an external site.
BGP Anomaly Detection Techniques: A Survey
https://www.researchgate.net/profile/Bahaa_Musawi/publication/309519246_BGP_Anomaly_Detection_Techniques_A_Survey/links/5a63db73aca272a1581bf3ea/BGP-Anomaly-Detection-Techniques-A-Survey.pdfLinks to an external site.
A Forensic Case Study on AS Hijacking: The Attacker’s Perspective
http://www.sigcomm.org/sites/default/files/ccr/papers/2013/April/2479957-2479959.pdfLinks to an external site.
An Analysis of Using Reflectors for Distributed Denial-of-Service Attacks
https://www.engineering.iastate.edu/~daniels/cpre592TD/readings/Anonymity_and_Concealment/paxson01analysis.pdfLinks to an external site.
Stellar: Network Attack Mitigation using Advanced Blackholing
https://dl.acm.org/doi/10.1145/3281411.3281413Links to an external site.
Inferring BGP Blackholing Activity in the Internet
https://dl.acm.org/doi/10.1145/3131365.3131379Links to an external site.
Next Gen Blackholing to Counter DDoS
https://ripe78.ripe.net/presentations/9-RIPE_Presentation_MW.pdfLinks to an external site.
Book References
Kurose-Ross Edition 6th, Section 8.1
Secure communications
There a 4 properties of secure communication:
- Confidentiality: The message can only be read by the person who was the intended recipient of the message.
- Integrity: The message was received as intended and has not been manipulated.
- Authentication: The person who you are talking to is who you think they are.
- Availability: You can communicate when you need to through this channel.
DNS abuse
Attackers have developed techniques abusing the DNS protocol to extend the uptime of domains that are used for malicious purposes (e.g., Command and Control hosting infrastructure, phishing, spamming domains, hosting illegal businesses, and illegal content). The ultimate goal of this abuse is to remain undetectable for longer.
These techniques have their roots in legitimate DNS-based techniques that legitimate businesses and administrators use.
Round robin DNS (RRDNS)
Link to originalRound robin DNS (RRDNS)
Round Robin DNS is a technique used by large websites to manage and distribute incoming traffic across multiple servers at a single location. When a DNS request is made, RRDNS responds with a list of IP addresses (A records) for the requested domain. These addresses are rotated in sequence with each request, ensuring that no single server is overloaded with too many requests.
The DNS client, which receives this list, can select an IP address based on various strategies, such as always choosing the first address or selecting the one closest in terms of network proximity. Each IP address in the list has a Time to Live (TTL), which dictates how long the address remains valid. If a DNS lookup is repeated before the TTL expires, the client receives the same list of IPs but in a different order, further balancing the traffic across servers.
DSN-based content delivery
Link to originalDSN-based content delivery
Content delivery network (CDN) use DNS-based methods to efficiently deliver content by distributing it across multiple servers worldwide. When a user requests a service via DNS, the CDN determines the “nearest edge server” based on factors such as network topology and current link characteristics. This server’s IP address is then returned to the user’s DNS client, ensuring that content is delivered from a location that is geographically or network-proximity closer to the user.
This approach enhances responsiveness and availability because the content is served from a closer location, reducing latency. CDNs also have the ability to quickly adapt to changes in network conditions due to their use of shorter TTLs compared to traditional round-robin DNS. This ensures optimal performance by dynamically redirecting traffic to the best available server based on real-time network conditions.
Fast-Flux Service Networks (FFSN)
Link to originalFast-Flux Service Networks (FFSN)
Fast-Flux Service Networks (FFSN) extend the principles of Round robin DNS (RRDNS) and Content delivery network (CDN) to enhance resilience and scalability, but they are often exploited by spammers and cybercriminals. FFSNs employ a technique where DNS responses rapidly change, featuring a very short Time to live (TTL) compared to RRDNS and CDNs. Each DNS lookup returns a different set of IP addresses from a larger pool of compromised machines.
These compromised machines, known as flux agents, act as intermediaries between the user’s request and the main control server (mothership), which hosts the actual content. When a user makes a request to a domain hosted on an FFSN, the DNS lookup provides several IP addresses of these flux agents. After the TTL expires, a new lookup returns a different set of IP addresses, complicating efforts to shut down malicious activities.
In this setup, the flux agents receive the user’s request and forward it to the control server. The control server sends the requested content back to the flux agents, which then deliver it to the user. This network structure makes it difficult to pinpoint and disable the source of malicious content, as shutting down one or even several IP addresses does not disrupt the overall operation of the network. These flux agents are often distributed across various countries and different Autonomous Systems, further enhancing the network’s resilience against takedown efforts.
/../../images/ffsn_explanation.png)
Rouge network detection
There are different approaches to detecting rouge networks. The most intuitive method is to see if they are hosting bad actors.
Finding rouge networks (FIRE)
Link to originalFinding rouge networks (FIRE)
The FIRE (FInding Rogue nEtworks) system is designed to monitor the Internet for rogue networks—networks primarily used for malicious activities such as phishing, hosting spam pages, and distributing pirated software. It utilises three main data sources to identify potential rogue networks:
- Botnet Command and Control Providers:
- Monitors networks hosting command and control (C&C) servers for botnets, focusing on IRC-based and HTTP-based botnets.
- These networks are chosen by bot-masters to avoid take-down.
- Drive-by-Download Hosting Providers:
- Detects networks hosting web pages that exploit browser vulnerabilities to install malware without user interaction.
- Phish Housing Providers:
- Tracks URLs of servers hosting phishing pages that mimic legitimate sites to steal sensitive information. These pages are usually short-lived and hosted on compromised servers.
The key difference between rogue and legitimate networks is the duration of malicious activity. Legitimate networks typically remove harmful content quickly, while rogue networks may host malicious content for extended periods. By ignoring IP addresses active for only a short time, the system filters out temporary abuses on legitimate networks.
FIRE aggregates daily lists of malicious IP addresses from these data sources and analyzes them to identify rogue Autonomous system (AS). It does this by comparing the ratio of malicious IP addresses to the total number of IP addresses owned by each AS, highlighting the most malicious networks.
The approach has a couple downsides:
- It is infeasible to monitor all networks all the time.
- It takes a long time for malicious IPs to get on the back list.
- This struggles to distinguish between bad networks and networks that are curntly being misused but are not themselves bad (such as a service that hosts websites for other people).
We could instead look at the network topology of the system to see if it is behaving like a bad actor.
ASwatch
Link to originalASwatch
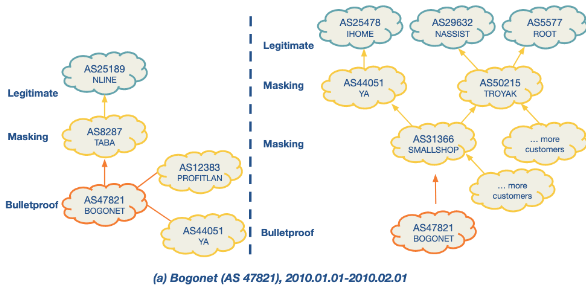
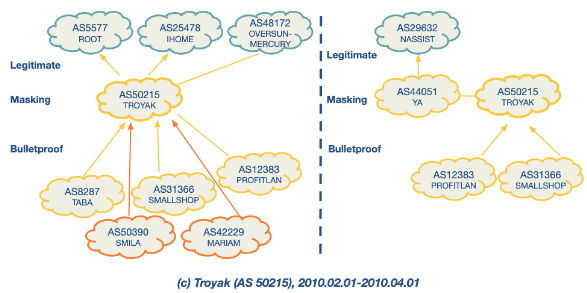
ASwatch is a system that identifies malicious Autonomous system (AS) by analysing their routing behaviour, focusing specifically on “bulletproof” networks run by cybercriminals. Unlike other approaches that might rely on data from network traffic or content, ASwatch exclusively examines control plane information, which pertains to how networks route data.
Bulletproof Networks: These are malicious networks that change upstream providers frequently and connect with shady networks to avoid detection. They display distinct interconnection patterns and control plane behaviors compared to legitimate networks.
ASwatch operates in two main phases:
- Training Phase:
- Data Collection: ASwatch collects data on known malicious and legitimate ASes, tracking their routing behavior and relationships with other networks over time.
- Feature Extraction: It extracts three main types of features from this data:
- Rewiring Activity: Looks for frequent changes in customers/providers and connections with less popular or shady providers.
- IP Space Fragmentation and Churn: Malicious ASes often advertise smaller BGP prefixes and frequently change their advertised IP address ranges to evade detection.
- BGP Routing Dynamics: Analyzes patterns in BGP announcements and withdrawals, noting that malicious ASes have different patterns compared to legitimate ones.
- Model Training: Using supervised learning, ASwatch trains a model to distinguish between the behaviors of malicious and legitimate ASes based on the extracted features.
- Operational Phase:
- Feature Calculation: For any unknown AS, ASwatch calculates the same set of features.
- Reputation Scoring: The trained model assigns a reputation score to the AS. An AS is flagged as malicious if it consistently receives a low reputation score over several days.
There are some examples below of suspicious behaviour.

Lastly we can instead of looking at if a network is behaving badly work out if the network is likely to be breached or to have been breached. This allows us to know if we can trust that network even if it is operated with good intentions.
This system predicts the likelihood of a security breach within an organisation using externally observable features. It uses these features to train a Random forest model, making it callable to all organizations. The features fall into three main categories:
- Mismanagement Symptoms:
- Open Recursive Resolvers: Misconfigured DNS resolvers that can be exploited.
- DNS Source Port Randomization: Servers lacking this feature are more vulnerable.
- BGP Misconfiguration: Short-lived routes indicating routing issues.
- Untrusted HTTPS Certificates: Detection of invalid certificates via TLS handshake.
- Open SMTP Mail Relays: Servers improperly configured to filter mail, increasing risk.
- Malicious Activities:
- Spam Activity: IP addresses involved in spam, identified by services like CBL and SpamCop.
- Phishing and Malware: Detection of phishing and malware sources via platforms like PhishTank.
- Scanning Activity: IP addresses involved in scanning detected by monitors like Dshield.
- Security Incident Reports:
- VERIS Community Database: A collection of over 5000 cybersecurity incidents.
- Hackmageddon: Aggregates monthly security incidents.
- Web Hacking Incidents Database: Repository of cyber security incidents.
Model and Evaluation:
- Random Forest Classifier: Trained using 258 features, including the ones described above, along with statistical secondary features and organization size.
- Baseline Comparison: Compared against a Support vector machines (SVM).
- Output: The model provides a risk probability which, when thresholded, gives a binary class label indicating breach likelihood.
- Data Handling: Training-testing splits are time-based to ensure sequential data integrity.
- Accuracy: The model achieves an accuracy of 90% with the optimal parameters.
This system effectively uses external indicators of mismanagement, malicious activity, and past incidents to predict the probability of future breaches in an organization’s network.
BGP hijacking
BGP Hijacking
Link to originalBGP Hijacking
This is a class of attacks that use the BGP protocol as its method of attack. This falls into 3 categories:
- Classification by Affected Prefix: In this class of hijacking attacks, we are primarily concerned with the IP prefixes that are advertised by BGP.
- Exact prefix hijacking
- Sub-prefix hijacking
- BGP squatting
- Classification by AS-Path announcement: In this class of attacks, an illegitimate AS announces the AS-path for a prefix for which it doesn’t have ownership rights.
- Type-0 hijacking
- Type-N hijacking
- Type-U hijacking
- Classification by Data-Plane traffic manipulation: In this class of attacks, the attacker intercepts traffic between two users and manipulates it.
- Blackholing attack
- Man-in-the-middle attack (MM)
- Imposture attack (IM)
There are different reasons attempt these attacks:
- Human error: Accidental misconfiguration of routers can lead to this type of attack. E.g. China Telecom accidentally leaked a full BGP table that led to large-scale Type-0 hijacking
- Targeted attack: This is normally done by someone trying to intercept network traffic and carry out a Man-in-the-middle attack (MM), a Type-N hijacking or a Type-U hijacking. E.g. Visa and Mastercard were hijacked by Russian networks in 2017 using this.
- High impact attack: Here someone is obviously trying to cause wide spread outages. E.g. Pakistan Telecom in a Type-0 hijacking with a Sub-prefix hijacking, essentially blackholing all of YouTube’s services worldwide for nearly 2 hours.
Defence against BGP Hijacking
ARTEMIS
Link to originalARTEMIS
ARTEMIS is a system designed to detect and mitigate BGP Hijacking, operated locally by network operators to protect their own prefixes. The system is based on several key ideas and can be found in this paper.
This works in the following way.
- Write a configuration File: Lists all prefixes owned by the network, created by the network operator.
- BGP Updates Mechanism: Receives updates from local routers and monitoring services.
- Anomaly Detection: Compares received BGP updates against the configuration file to detect anomalies in prefixes and AS-PATH fields.
ARTEMIS can detect different types of BGP prefix hijacking attacks by monitoring for unusual patterns in BGP announcements.
The system aims to minimise false positives and false negatives. Operators can prioritise between accuracy and speed or opt for fewer inconsequential FNs at the cost of higher FPs.
This is achieved by
- Prefix Deaggregation: The affected network announces more specific prefixes to counteract hijacked prefixes. For example, if a prefix 208.65.153.0/24 is hijacked, the network could announce 208.65.153.128/25 and 208.65.153.0/25.
- Multiple Origin AS (MOAS): Third-party organisations announce the hijacked prefixes from their locations. This attracts global traffic to the third party, which scrubs it and tunnels it back to the legitimate AS.
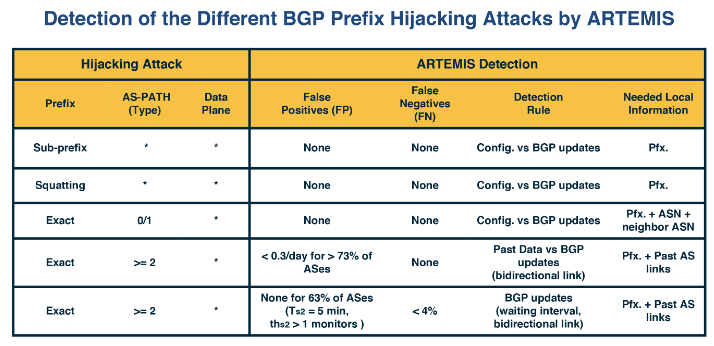
Within the paper it highlighted.
- Outsourcing BGP Announcements: Having an external organisation manage BGP announcements is highly effective in combating BGP hijacking.
- BGP Announcements vs. Prefix Filtering: Outsourcing BGP announcements is more optimal compared to the current standard defence mechanism of prefix filtering.
Distributed Denial-of-Service (DDoS)
Distributed Denial-of-Service (DDoS)
Link to originalDistributed Denial-of-Service (DDoS)
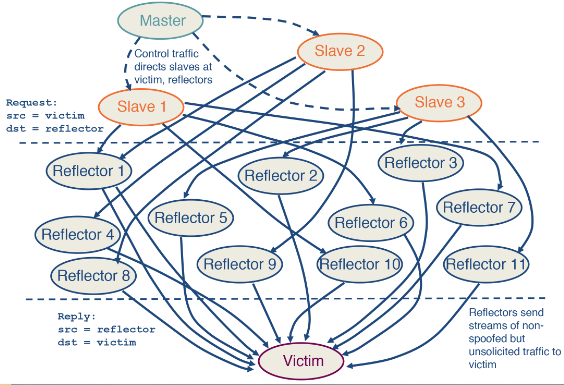
This is an attack against a service where you flood it with requests that it can not handle. This cause the service to crash denying access to it for other users.
The diagram demonstrates the simplest form of attack but this has many variants such as Spoofing and DDoS reflection and amplification.
Spoofing
Link to originalSpoofing
Spoofing is the process of replacing the IP source field of a request.
In the context of DDoS attacks this can be done in two ways:
- Changing the address to another legitimate server to waste resources and bandwidth.
- Changing the address to the host you are attacking so the response is sent to the server under attack.
DDoS reflection and amplification
Link to originalDDoS reflection and amplification
Instead of attacking your target directly in DDoS attack - you can instead find legitimate services that respond to requests (for example when opening a TCP connection). You can make requests to such services where you spoof the source IP as your target. This has two advantages:
- It is hard to block as the servers sending the request to the target could be services it relies upon or would need to talk to.
- The services that could blocks the requests are not the same as the one that is suffering the damage causing a coordination issue.
Defence against DDoS
Traffic Scrubbing Service
Link to originalTraffic Scrubbing Services
A scrubbing service diverts the incoming traffic to a specialised server, where the traffic is “scrubbed” into either clean or unwanted traffic. The clean traffic is then sent to its original destination. This offers fine-grained filtering but at a high monetary and bandwidth cost.
Access control list (ACL) filters
Link to originalAccess control list (ACL) filters
Access Control List filters are deployed by ISPs or IXPs at their AS border routers to filter out unwanted traffic. These filters, whose implementation depends on vendor-specific hardware, are effective when the hardware is homogeneous, and the deployment of the filters can be automated. The drawbacks of these filters include limited scalability, and since the filtering does not occur at the ingress points, it can exhaust the bandwidth to a neighbouring AS.
BGP Flowspec
Link to originalBGP Flowspec
BGP Flowspec is an extension of BGP designed to allow the creation and propagation of detailed traffic flow filtering rules. These rules can be applied across different ASs.
The following table shows the available components to select a flow:
After you have specified a particular flow you can select an action associated to it such as traffic-rate, redirect or drop. This will be implemented at the boarder router.
This has the following advantages:
- Fine-Grained Control: Flowspec allows for detailed and specific traffi management rules.
- Centralized Management: Leveraging the BGP control plane, it enables easy and simultaneous updates to all routers in a network.
- Effective Mitigation: It is particularly effective in mitigating DDoS attacks within a single network or AS.
Though comes with some downsides:
- Inter-Domain Deployment: Flowspec’s effectiveness diminishes when rules need to be applied across multiple AS, especially if these AS belong to competing networks. Trust and cooperation are crucial but often lacking.
- Scalability Issues: For large-scale attacks originating from many sources, creating numerous rules or aggregating sources into a single prefix can be challenging and inefficient.
Practically due to the need for trust this is only deployed within a AS and is not used more broadly.
ACL vs. Flowspec: Unlike traditional Access Control Lists (ACLs) that must be manually configured on each router, Flowspec rules can be propagated using the BGP protocol, making network-wide rule deployment more efficient.
Real-World Applications: ISPs and large enterprises often use BGP Flowspec to protect their networks from DDoS attacks by dynamically adjusting traffic rules based on current threats.
By understanding and leveraging BGP Flowspec, network administrators can better protect their infrastructures from DDoS attacks, ensuring smoother and more secure network operations.
Lastly we consider Blackholing (BH).
Blackholing (BH)
Link to originalBlackholing
This is when a server drops message either intended for itself or another server. This is done in the case of a DDoS attack to protect the service being attacked. Though can be used for malicious purposes as well in the case of a Blackholing attack.
BGP Blackholing
Link to originalBGP Blackholing
This is a method of initiating blackholing in the event of a DDoS attack using an upstream service.
This works in the following stages:
- Announcement: The victim AS under attack announces the targeted destination IP or prefix to its upstream provider or Internet Exchange Point (IXP).
- Propagation: The upstream provider or IXP then advertises a more specific prefix and modifies the next-hop address to divert the traffic to a null interface.
- Blackhole Community: The blackholing message is tagged with a specific BGP Communities attribute to differentiate it from regular routing updates. This is normally the community 666.
There are two main ways this is implement.
- Using an Upstream Provider:
- The victim network announces a blackholing message to its upstream provider, specifying the attacked IP and the blackholing community.
- The provider then recognises this message and sets the next-hop field to a blackholing IP, effectively discarding all traffic to the attacked IP.
- Using an Internet Exchange Point (IXP):
- If the victim network is part of an IXP, it sends a blackholing message to the IXP route server.
- The route server then propagates this message to all connected IXP member networks, which drop the traffic to the blackholed IP.
Key Benefits of BGP Blackholing:
- Effective Mitigation: Stops high-volume attacks close to their source, preventing them from reaching and overwhelming the target.
- Scalability: Can be implemented quickly by upstream providers or IXPs to protect multiple networks.
- Cost-Efficiency: Reduces the need for expensive DDoS mitigation services by leveraging existing BGP infrastructure.
Challenges and Considerations:
- Collateral Damage: Legitimate traffic to the blackholed IP is also dropped, which can disrupt normal operations.
- Coordination: Effective implementation requires coordination and trust between the victim network and its upstream providers or IXPs.
- Community Attributes: The blackhole community attributes must be publicly available and correctly implemented to ensure proper functioning.
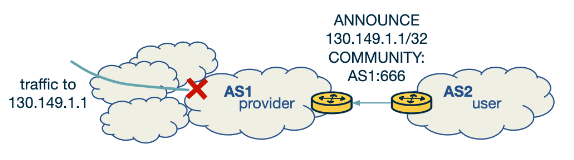
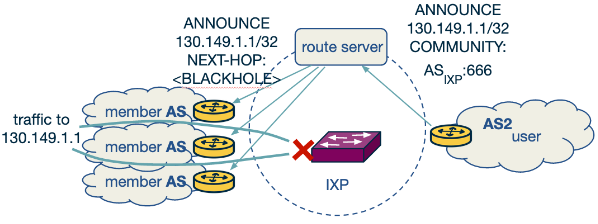
When implemented in an IXP if one of the participants does not accept the BH message then this can render the who excise worthless.