Week 15 - Distributed shared memory
Additional reading
Distributed shared memory
Distributed shared memory is similar to a distributed file system however all clients are also clients to others. They share the state mutually.
Peer distributed application
Link to originalPeer distributed application
A Peer distributed application is a distributed algorithm where nodes in the network act not only as clients (receivers of data) but also as servers (or producers). This is distinguished from a Peer-peer model as there may still be some privileged nodes in the network that handle more of the management workload.
Distributed shared memory (DSM)
Link to originalDistributed shared memory (DSM)
Distributed shared memory is a Peer distributed application which enables machines to share their memory and have access to memory which does not exist on the machine locally. This extends the machines effective memory size. Though the payoff is some memory access will be slower.
The network will try to intelligently replicate memory locations to reduce memory latency for the machine. However this will required consistency protocols to ensure any replicated state is consistent between machines.
This technology is become more relevant in data centers since the development of Remote direct memory access (RDMA).
Remote direct memory access (RDMA)
Link to originalRemote direct memory access (RDMA)
Remote direct memory access is data-center technology which extends Direct memory access (DMA) to work between servers.
Hardware vs software support
The basic concept in distributed shared memory is when memory access is not local it goes via the network.
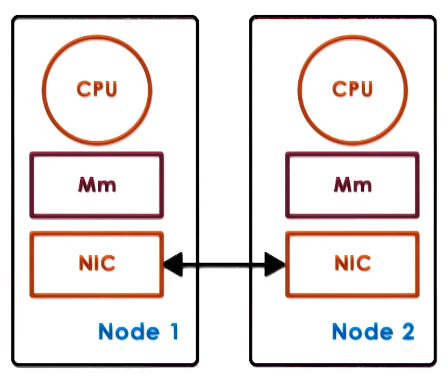
Whilst in data-centers they use hardware such as Remote direct memory access (RDMA) this is an expensive option. Other applications can achieve the same using software.
Sharing granularity
When looking at shared memory within a processor the share locations at the variable level. However if we go out to the network for each variable that will cause too large a slowdown for a system. Instead we can to it at a less granular level:
- Page level: The OS understands memory at the page level which makes this an attractive option.
- Object level: If all nodes are using the same language they can share at a larger object level.
False sharing
If two clients are using a shared page, one writes and only uses a variable
the other writes and only uses the variable . If and are on the shared page the page will have to be kept in sync between the two machines whilst in reality there is no shared state.
Access patterns
When designing a system to share memory it is good to understand how the memory will be used:
- Single reader/single writer
- Multiple reader/single writer
- Multiple reader/multiple writer
This lecture will cover the last of these.
State management
There are two techniques for moving state between members of our network.
Migration
When a new user wants the data we move it off the node it is currently stored onto the node that needs to use it. This makes sense for the single reader/writer case however will require a lot of data movement in the network if multiple entities are using the data at the same time. The cost of moving the data ideally should me amortized across multiple operations on it.
Replication
Instead of the data just being present on a single node it is copied onto multiple nodes who are using the data. (This is similar to caching.) This will allow multiple users quick access to the data whoever will require consistency management to keep replicated state aligned.
Difference between Caching and replicated
In a cached setup there is a single source of truth and clients hold a copy of that which is backed up by the source of truth. However in replication no one source is privileged over another.
Consistency management
First lets review the consistency management we have seen before. Shared memory on a processor used:
- Write-invalidate
- Write-update
These both happened as soon as a write happened which may course too much overhead in distributed settings. In distributed file system we saw two different methods.
- Push invalidation’s when data is written to. This is considered proactive, eager or pessimistic and will cause more network overhead.
- Pull modifications periodically. This is considered reactive, lazy or optimistic. This should reduce network overhead but risks state being out of sync.
When these methods get triggered depends on the consistency model for the shared state.
DSM Architecture
We will look at one design for a page based OS-supported Distributed shared memory (DSM) system.
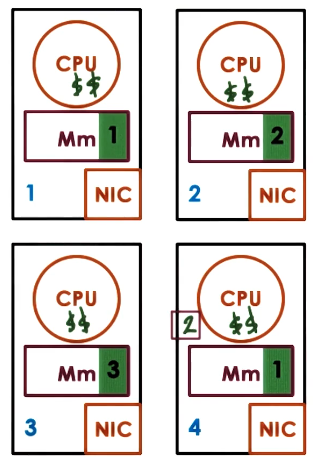
- Each node will share part of its memory pages to the Distributed shared memory (DSM).
- It will implement local caches to reduce network latency.
- All nodes are responsible for part of the distributed memory.
- The node where the memory is first created is allocated as its home node. This node will handle all the management for that memory.
- The node that contains the current true state is the memory owner (could be different to the home node).
- Explicit replicas can be generated for load balancing, performance, or reliability.
- The home node tracks replicas and caches to maintain consistency.
To maintain this system we need a way to identify each page of memory and speak to the home node. There are two methods to identifying pages.
- Let the page ID consist of the home node ID + some local page ID.
- Give the page a fixed ID and distribute a map from IDs to home nodes.
The first method is simple but means if a node leaves the system for any reason it invalidates all the memory it war managing. The second allows for updates to the home node though relies on replicating that map to all nodes in the system.
For each page we require to store metadata about the page. This will just need to be stored on the home node so can be partitioned.
For this to work we need to intercept all messages that involve writing or reading shared memory.
- When these messages are for memory that is present locally we want to intervene as little as possible.
- However for remote memory we will need to handle that using are network.
To do this we need hardware support in the MMU and OS support.
- Access to remote memory should trap into the OS.
- This should raise an error if the memory is not available.
- If the access is valid we need to contact the home node for that memory.
- If it is locally cached we need to perform and coherence operations required.
- We can us other MMU state such as dirty pages to assist with this.
Consistency model
Consistency model
Link to originalConsistency model
A consistency model is an agreement between memory and the software that is using it. More precisely it guarantees certain behavior of the memory if the software behaves in a certain way. The guarantees it can make relate to access order and propagation and visibility of updates.
Strict consistency
Link to originalStrict consistency
This is a consistency model that guarantees all updates are visible everywhere immediately. This is not practical system and is only a theoretical model.
Sequential consistency
Link to originalSequential consistency
This is a consistency model that has the following rules:
- Memory updates from different processors may be arbitrarily interleaved.
- All processes will see the same interleaving.
- Operations from the same process always appear in the order they were executed.
Causal consistency
Link to originalCausal consistency
This is a consistency model where a system is causally consistent if, for any two operations
op1andop2, whereop1causally precedesop2, then every process that observesop2must have already observedop1.
Weak consistency
Link to originalWeak consistency
Weak consistency is a consistency model that introduces a new operation - synchronize. The model only guarantees that all operations before all synchronization points will be visible in the order of the synchronization points when any process calls synchronize. There are variations of this:
- Single sync (like above).
- Separate sync per subset of state (e.g. page)
- Separate entry/acquire vs exit/release operations.