Week 14 - Distributed file systems
Additional reading
“Caching in the Sprite Network File System”
Distributed file system
Distributed file system (DFS)
Link to originalDistributed file system (DFS)
A file system is distributed if the files represented within the system do not necessarily exist on the machine that is hosting that file system. In this case access to different files will require network calls.
There are different models for distributing files:
- Client/server model: A client with the file system talks to a single server who has all the files.
- Client/server-cluster: A client contacts a cluster of servers who all have files the client can get files from. This can take different forms
- Replicated: Each server has all the files.
- Partitioned: each server serves part of the file system.
- Both: Files are replicated and partitioned between machines (this is functionally how most large providers operate).
- Peer-to-peer: A cluster of computers act as peer backups for one another. (This will be covered in more detail next lecture.)
Implementation
There are different models for a Distributed file system (DFS) in the client server model.
Download model
In this model the client downloads the whole file from the server, applies any edits locally and re-uploads the file to the remote server.
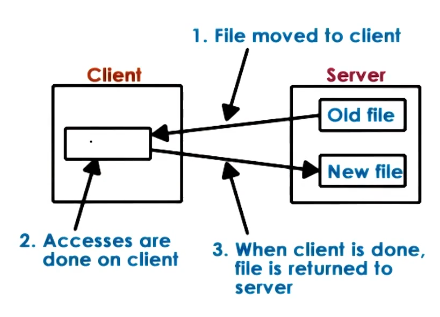
This means:
- edits to the file are done locally and are fast,
- the client has to download the entire file and upload it even if they only need to edit a small part, and
- the server loses all control of the file whilst the client is using it which limits sharing.
Fully remote model
In this model all commands the client wishes to do to the file are sent to the server who applies them on the server directly.
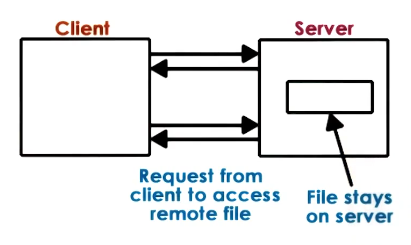
This means:
- file accesses are centralized,
- Consistency is easy to reason about, but
- every file operation pays the network cost.
Remote access with caching
In this model we allow clients to locally store parts of files. However the clients will notify the server of their interactions with the file - such as if they edit it or delete it. Equally the server is responsible for updating their cache if other clients change the file.
This means:
- Low latency operations on cached files,
- Server load is reduced in comparison to the fully remote model,
- Server is aware of what clients are doing,
- Server has control into whihc accesses can be permitted, however
- The server is a lot more complex to handle all these consistency mechanisms.
State management
The server can either be stateful or stateless this has implications on the design of the server.
Stateless
This works in both extreme models but does not work with caching. This means:
- Cannot support caching or more complex consistency management.
- Every request will need to contain the full context, meaning larger message sizes.
- No resources on the server are used to maintain the state.
- On failure you can just restart the application.
Stateful
Needed for the caching model. The server tracks the state of the different clients.
- Can support locking, caching, and incremental operations.
- On failure we will need checkpointing or a recovery mechanism.
- Overheads on the server to maintain the state and consistency between the clients.
Caching
This means that clients store a portion of the file system locally to do operations. When we do this we need to introduce coherence mechanisms.
For example, if two clients have the file F cached locally. When one of them updates the file how does the second client find out about it. From processor memory we had two options for this:
- Write-update: Update the cache of the second client.
- Write-invalidate: Alert the client to delete their cache.
However with DFS we have much larger network latency than in CPU so the question about when this happens is important:
- Does the client notify the server when changes happen, or
- Does the server poll for changes in the local cache.
File sharing semantics
When two processes access a file on one machine changes become instantly available. (This is called UNIX semantics.)
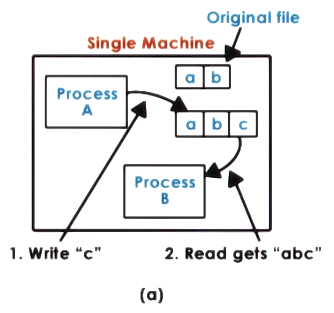
However on two machines this might not be the case and edits can happen on ‘stale’ data if the consistency model is not strong enough.
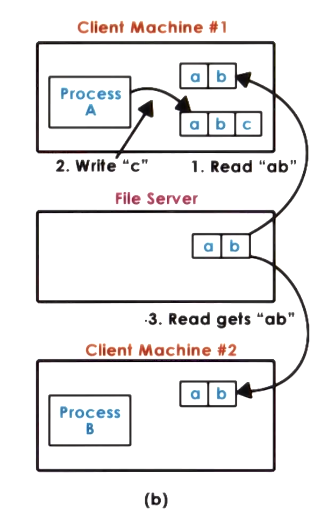
Session semantics: This refers to syncs on open and close operations of a file. With the time between the open and close being a session. In this case the client checks on open they have the latest file and saves back to the server on close.
Sessions can be long if the client is editing a file for a long time - therefore it can be useful to introduce periodic updates. This could involve:
- The client writes-back periodically.
- The server invalidates the caches periodically which introduces a bound on inconsistency.
- To support the above Distributed file system (DFS) can introduce flush/sync operations.
The server can implement immutable files which never get modified only have new files created.
The server can implement transactions so that all edits to a file are atomic and based on a particular version.
Access patterns
When choosing a type of semantics it is important to understand the file access patterns:
- How often are files shared,
- How often are files written too,
- Importance of consistent view, or
- Does the access pattern change based on the type of file? Does it change for directories?
Replication
Replication is the process of keeping copies of the same file on multiple machines. This has the advantages of:
- Load balancing,
- availability, and
- fault tolerance.
Though you need to then not only keep consistency between the client and the server but also between the servers. This means writes become more complicated as they need to handle synchronicity. There a multiple different methods to handle this:
- Writes get sent to all machines (slow), or
- Write to one and propagate to others.
Machines will need to keep in sync with each other, however when there is a descrepency there must be a method to bring everyone back together, e.g. voting.
Partitioning
This is where files are separated out onto different machines, so not all the state is held on any one of them. This has the advantages of:
- Higher availability (less requests per server),
- Scalability (more storage), and
- Single file writes are simpler than replicated setting.
Though your fault tolerance reduces as any one server going down loses you files. Load balancing is harder due to different access patterns per file.
Normally replication and partitioning are combined to mitigate the flaws of both systems.
NFS
Network file system (NFS)
Link to originalNetwork file system (NFS)
This is a distributed file system developed by Sun. This uses Remote Procedure Calls (RPC) to communicate between servers and client. When the client opens a request to a file, it creates a virtual file descriptor which contains details about the server and file. This is used by the client to read/write to the server. If the server dies that descriptor returns an error so the client knows there was an issue with the request.
/../../images/nfs_arcitecture.png)
This application has changed over the years, NFSv3 is stateless whilst NFSv4 is stateful. The change made NFS to support caching and locking.
- It uses session-based caching.
- The server gets periodic updates from the client, every 3 seconds for files and 30 seconds for directories.
- Directory change less, and are easier to merge.
- When a client checks a file out it avoids the update checks for that file.
- It uses lease-based locks. These are time bounded and need to be extended or released within that window.
- There are reader/writer locks with the ability to upgrade from read to write.
Sprite distributed file system
Whilst not a production distributed file system like NFS the sprite network was a research file system. However it was built and used in Berkley and the design decisions were based of traces of network usage within real use cases. The collected the following data on their use case:
- 33% of all file accesses are writes.
- → Caching is ok, but write-through semantics is not sufficient.
- 75% of files are opened for less than 0.5 seconds.
- 90% of files are open for less than 10 seconds.
- → Session semantics will cause too many connections to the server.
- 20-30% of new data is deleted within 30 seconds.
- 50% of new data is deleted within 5 minutes.
- → Write back on close not really necessary.
- File sharing was rare.
- → No need to optimize for concurrent access, but must support it.
With this data they made the following conclusions.
- Cache with write-backs: Every 30 seconds write-back blocks that have NOT been modified for the last 30 seconds.
- Dirty files are synced on read: When a users reads a file that is being modified by another user, it will sync those blocks to server for that client.
- Open goes to the server: Directories can not be cached so will need to go to the server for that.
- Disable the cache on concurrent writes: In this rare case, switch to both clients going via the server for writes.