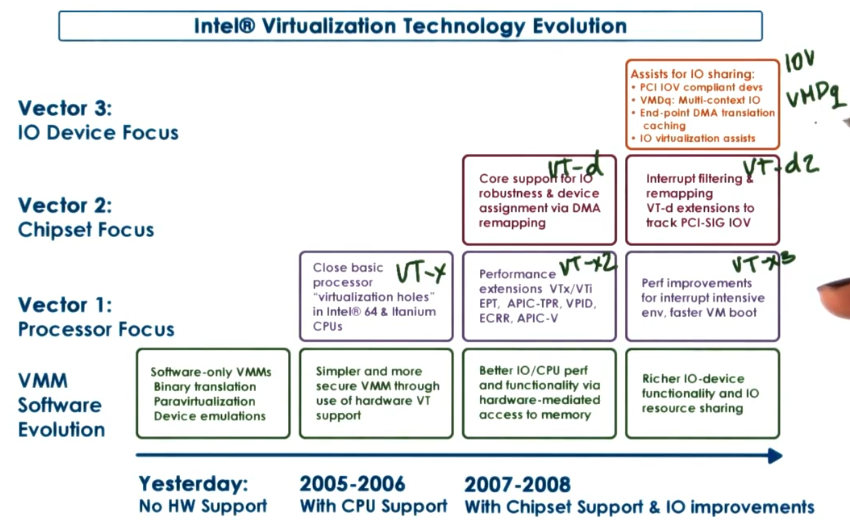
Week 12 - Virtualization
Additional reading
Virtualization
Virtualization
Link to originalVirtualization
A virtual machine is an efficient, isolated duplicate of the real machine. This is enabled by a Virtual machine monitor (VMM).
Virtual machine monitor (VMM)
Link to originalVirtual machine monitor (VMM)
A virtual machine monitor enables virtualization by providing an environment:
- fidelity: essentially identical with the original machine.
- performance: where programs show at worst only minor decrease in speed.
- safety and isolation: where the VMM is in complete control of the system resources.
/../../images/vmm.png)
Benefits for vitualisation:
- Consolidation: Allows you to split one machine into many, allowing you to consolidate different applications that need different environments to run.
- Migration: Makes it easy to move applications from one machine to another.
- Security: Isolates applications from one another.
- Debugging: Makes it easy to spin up similar instances of crashed programs to debug.
- Support for legacy OS: Easy to host an application that needs a legacy operating system to run.
- Support for OS research: Makes it easy to change an operating system and observe the effects of that.
There are two main methods of virtualization:
- Bare-metal: This is where a hypervisor is installed on top of the hardware.
- Hosted: This is where the hypervisor is installed on top of another OS.
Bare-metal
In this model the hypervisor is in direct control of the hardware. The main difficulty of the model is integrating different devices - as device manufacturers would need to write a device driver for the hypervisor also. The way most hypervisors get around this is by hosting a privileged VM that integrates with devices. This also runs other management tasks.
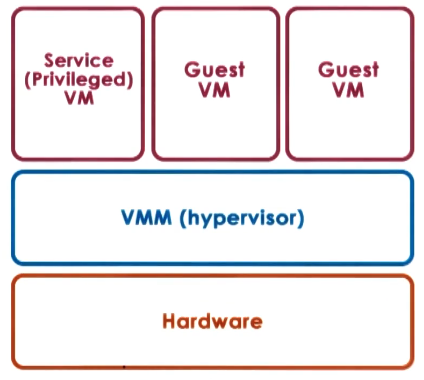
There are two main hypervisor producers:
- Xen (open source or Citrix):
- This uses a privilaged VM.
- ESX (VMware):
- Largest market share.
- Can force server device manufacturers to release drivers.
- Controlled using APIs
Hosted
In the hosted model the VMM runs as module on a host OS. This module provides hardware interfaces to VM’s and deals with VM context switching. The advantage of this mode is you can utilize all the components of the host VM making the VMM smaller in size.
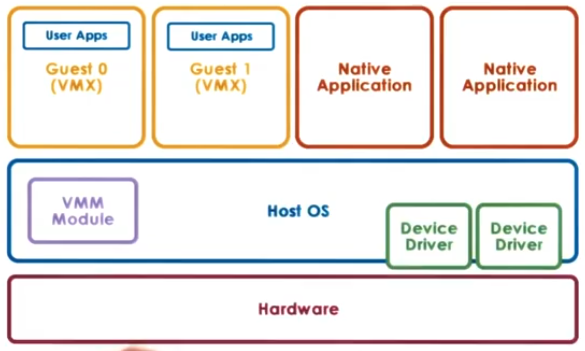
Examples:
- Kernel-based VM (KVM) which is linux based.
- Uses an OS module on the host and a QEMU for hard ware virtualization in the VM.
- Leverages the linux open source community.
Hardware protection levels
Hardware protection levels
Link to originalHardware protection levels
Within the CPU there are different privilege levels which software can reside in. This normally uses the ‘ring model’ in which there are 4 levels:
- Ring 0:
- Highest level of privilege which allows it to use all hardware operations.
- Used by the kernel, or core OS components.
- Ring 1 & 2:
- Intermediate privilege levels.
- Rarely used in modern operating systems.
- Intended to be used by drivers or services that existed between the user and the kernel.
- Ring 3:
- Lowest privilege level.
- Used by user-mode applications.
- Cannot directly access hardware.
When using a bare-metal hypervisor this introduces another set of distinctions. Root or non-root applications (so in total there are 8 levels).
- Root mode:
- Used by the hypervisor.
- Can control virtual machines and intercept privileged instructions.
- Non-root mode:
- Used by guest operating systems running inside virtual machines.
- Applications running here may believe they have full control of the resources but these instructions are intercepted by the hypervisor.
When running a normal OS then only 2 rings are really used:
- Ring 0: Used by the operating system.
- Ring 3: User applications running at this level.
However for bare-metal hypervisors they will run:
- Ring 0 (root): Hypervisor.
- Ring 0 (non-root): VM OS.
- Ring 3 (non-root): VM user applications.
Most hypervisors operate using a trap and emulate model. This entails:
- Letting as many operations from the guest OS go directly to the hardware as possible. Given it is only using the resources it was allocated in startup.
- This enables efficiency, to reduce context switching between the OS and the VM
- If the guest OS tries to do a privileged operation it does not have sufficient privilege for, this traps to the hypervisor:
Historic issues
In the past there was not root/non-root modes so the strategy was to run:
- Ring 0: Hypervisor
- Ring 1: Guest OS
- Ring 3: Applications
However, at the time 17 instructions required ring 0 level but would not throw a trap if sent from ring 1 - instead they would fail silently. This caused issues as no transfer of control was carried out but also the Guest OS would not know it did not know its operations were not carried out.
To achieve “full-virtualisation” a hypervisor wants to run guest OS unaltered. VMWare took to this approach and to solve the above issue invented a technique called binary translation. This took the binary instructions from the guest OS and scanned them for any of these 17 instructions. If the hypervisor found the OS was going to carry out any of the restricted operations it switched the binary instruction set for one that did not use it but still returned the OS to a state in which it would have arrived if it did. If not - the block executes at hardware speed.
This level of analysis introduced overhead which had to be mitigated by using tricks like caching and selective analysis (i.e. only on kernel code).
Another approach to this issue is called “paravirtualisation” with this you modify the guest OS so that it knows it is running on a hypervisor:
- It makes explicit calls to the hypervisor (hypercalls)
- These package context info,
- specify the desired call to the hypervisor, and
- trap to the hypervisor.
- This approach was taken by the open source Xen project, this got bought by citrix.
Memory virtualization
First lets talk about “Full-virtualization”.
- All guests OS expect contiguous physical memory, starting at 0.
- Though there are now 3 different addresses.
- Virtual: In a process on the guest OS.
- Physical: In the guest OS.
- Machine: In the hypervisor, i.e. what is actually on the hardware.
- The hardware still has the MMU and TLB to speed up memory mapping, we will want to use this to keep memory look up fast.
There are two options here, however only one is really used.
- Option 1: Multiple page tables:
- The guest OS maintains its own VA → PA mappings.
- The hypervisor maintains the PA → MA mappings that can be used by the MMU.
- This is too slow as we would need to do the first mapping all the time in memory.
- Option 2: hypervisor shadows the page tables.
- The guest OS maintains its page tables which go from VA → PA.
- The hypervisor shadows these page tables in the MMU and converts them to VA → MA under the hood.
- Hypervisor maintains consistency by write protecting the page tables from the OS then when the guest OS tries to write to them it traps and can apply its mapping to them directly.
In Paravirtualisation as the guest OS knows it is virtualised we do not need to maintain two different mappings - instead the guest OS registered its page tables to the hypervisor and it takes full control of the page table management on the MMU. The issue with this is it triggers a trap to the hypervisor on each call to edit a page table, which can be slow. So when changing the OS we can make optimizations like batching page table registration to amortise the cost over lots of operations.
In newer platforms these overheads have nearly been completely eliminated.
Device virtualisation
For CPU and RAM there is low level of diversity in the interfaces. However for generic devices this diversity is massive so virtualising device access is a complicated problem. There are 3 models taken to do this.
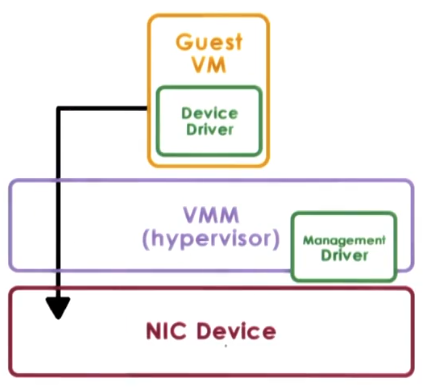
Pass through model
In this model the hypervisor directory passes operations from the guest OS to the device. This has the following considerations:
- The VM is provided with exclusive access to the device.
- The VM can directly access the device without a trap to the hypervisor.
- If multiple VMs need that device, sharing can be very complicated.
- The guest OS must have exactly the correct device driver for that device. This makes migration harder and couples applications to machines with exactly that device on it.
Hypervisor direct model
In this model the hypervisor intercepts any device accesses and translates them into a generic operation. This operation is then processed using the hypervisor and carried out on the device. The response is then converted back to what the guest OS expects the response to be.
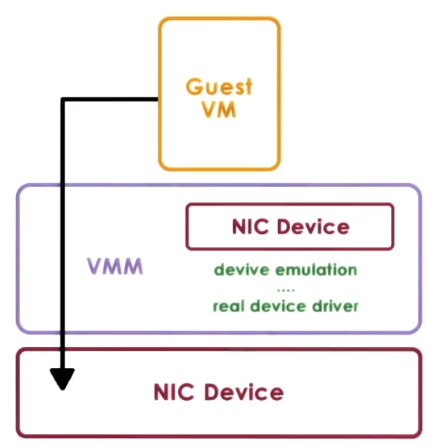
This has the following considerations:
- The guest OS is completely decoupled from the physical device.
- Sharing resources, migration, and dealing with device specifics becomes easy.
- This introduces latency into device operations.
- Device driver ecosystem will need to implement hypervisor compatible versions.
Split-device driver model
This model is limited to only paravirtualised hypervisors and requires them to be running a service VM. This uses two different device drivers:
- Backend device driver: Running on the service VM, this will be whichever device driver is needed to work with the device that is plugged into the machine.
- Frontend device driver: Running in the guest VM, this sends requests to the service VM to carry out the request on the behalf of the guest VM.
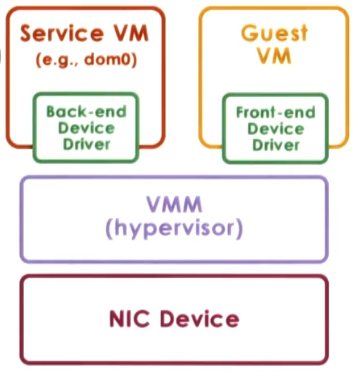
This model has the following considerations:
- Eliminate emulation overhead of the direct model.
- Allows for better management of shared devices.
- Can only be used on paravirtulaised systems.
Modern developments
Due to the benefits of virtualization the industry has been working to make virtualization easier:
- Updated the 17 operations that would not throw a trap, to throw a trap!
- Introduced root/non-root modes.
- Introduction of VM control structure to differentiate data used for one VM or another.
- Extended page tables and tagged TLB with VM ids so clearing the cache can be made more efficient.
- Multiqueue devices and interrupt routing.
- Security and management support.