Week 3 - Threading and concurrency
“An Introduction to Programming with Threads” by Birrell
Thread
Link to originalThread
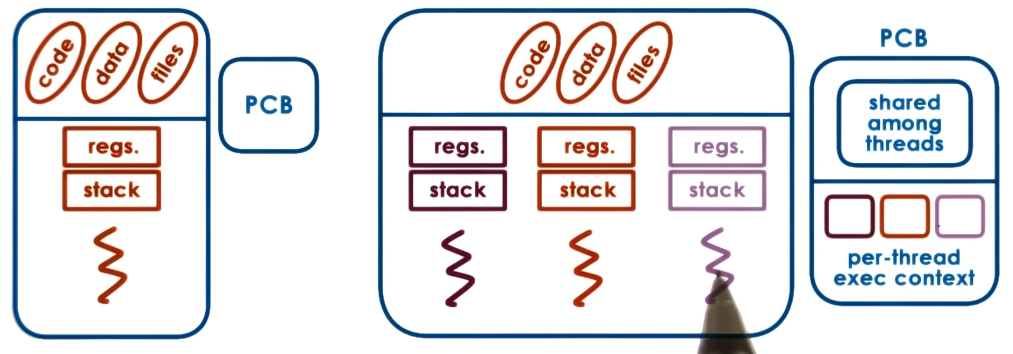
A thread is the smallest unit of execution within a process, representing a single sequence of instructions that the CPU can execute. Each thread within a process shares the process’s resources, such as memory and file handles, but operates with its own set of CPU registers, stack, and program counter. In the Process control block (PCB), the state of each thread is tracked, including its individual register values, program counter, and thread-specific data, while sharing the broader process-level information like memory space and O resources.
Visual metaphor
Threads are like workers in a toy shop:
- is an active entity
- Executing unit of toy order
- Works simultaneously with others
- many workers completing toy orders
- requires coordination
- sharing tools, parts, workstations
In comparison to a thread:
- is an active entity
- executing unit of a process
- works simultaneously with others
- many threads executing
- requires coordination
- sharing of IO devices, CPU, and virtual memory.
Difference between a process and a thread
Each process has its own address space and PCB whereas each thread in a process shares the same address space, code and data but has its own CPU registers, program counter, and stack. A thread does not have its own PCB but its state is tracked in the process PCB.
Benefits of multithreading
Threads allow us to parallelise a process over multiple cores without incurring the code complexity of Inter-process communication (IPC) or the overhead of multiple PCB instances. You can specialise threads for a particular task that needs the same items from the cache this allows you to run the task off a hot cache all the time.
Multi-threading on a single core also can be efficient. As one of the largest costs in context switching is to remap the address space the time it takes to context switch between threads is lower than that for processes. Therefore if you have O bound tasks using multi-threading can improve performance.
Downsides of mulitithreading
Now threads have access to the same virtual memory they can perform operations on the same bit of memory which can lead to unintended outcomes. For example two threads incrementing a number leading to the number only being incremented by one.
Concurrency control mechanisms
Mutual exclusion
You can limit certain actions to only be carried out by one thread at a time. This is called mutex.
Threads waiting
Similar to processes threads can enter a wait state for O operations or other conditions. This is controlled by condition variables.
Threads getting woken up
Threads can also wake each other up.
Thread creation
Threads interfaces are different between providers. In this course we follow on specific implementation.
Threads have a data-structure that tracks their current state. Containing data like:
- Tread ID,
- Process it belongs to,
- CPU register,
- stack,
- attributes.
A thread can start another thread using the Fork command (not the same as UNIX fork). This takes a program to run and the arguments and starts a new thread.
A thread can be terminated using the join command which makes the thread calling it wait till the joined thread finishes and then gets any returned value.
Different threads execute operations in a non-deterministic manner
If two threads are safely writing to a list the order of those writes are non-deterministic as it is up to the kernel to schedule them.
Mutex
Mutex
Link to originalMutex
A mutex is a lock on some shared operation between threads. For example accessing shared memory. To do the operation you must obtain the mutex (if some other thread has the mutex you enter a wait state). The mutex is just a data structure consisting of atleast:
- Status of the mutex,
- Current mutex owner, and
- List of threads waiting on the mutex.
Birrells original API used a context manager syntax but common apis use an lock and unlock command. The code in the context manager or between the lock and unlock commands is called the critical section.
Conditional variables (Mutex)
Link to originalConditional variables (Mutex)
A mutex may need special operations applied upon some condition being met. (For example processing a list when it is full.) To implement this we use data structure called conditional variable that holds at least:
Then an OS will offer 3 calls on the API:
- wait(mutex, condition): mutex is released and reacquired when the condition is met (i.e. they are notified about the condition).
- signal(condition): notify a single thread waiting on the condition it has been met.
- broadcast(condition): notify all threads waiting on the condition. (Though as they are all waiting on the mutex they only activate one at a time.)
Example: Reader/writer Problem
Suppose we want to read and write to some resource. We are fine with multiple threads reading the resource but we only want one writer ever writing to it and we do not want anyone reading from it at that time.
We could put a mutex on the resource operations though that would only let one reader access it at one time. Instead we make a proxy variable and put a mutex to access that. Lets consider the different states:
- No writer or reader accessing it (counter == 0),
- Any number of readers accessing it (counter > 0), or
- A single writer accessing it (counter == -1).
Mutex: counter_mutex
Condition: write_phase
Condition: read_phase
int: resource_counter
// Reader code
...
lock(mutex){
while (resource_counter == -1):
wait(mutex, read_phase)
resource_counter++
}
// READ RESOURCE
lock(mutex){
resource_counter--
if(resource_counter == 0):
signal(write_phase)
}
...
// Writer code
...
lock(mutex){
while (resource_counter != 0):
wait(mutex, write_phase)
resource_conter = -1
}
// WRITE RESOURCE
lock(mutex){
resource_counter = 0
broadcast(read_phase)
signal(write_phase)
}
...Use while on the condition in the critical section instead of if
There are multiple reasons this is best practice:
- This allows for multiple threads waiting on the same condition,
- Anyone thread might not be the first thread to access it after it has been released,
- The condition might have changed since it has been woken up.
The critical sections follow a similar structure.
lock(mutex){
while !predicate_for_ok_state:
wait(mutex, conditional_variable)
update state => update predicate
signal/broadcast conditional variables
}In this example the real critical code is not protected by a mutex which is the reading and writing of the resource. This proxy variable pattern is common and follows a general stricture.
Proxy variable pattern
When controlling an operation using a proxy variable it uses the following pattern:
// ENTER BLOCK
Controlled operation
// EXIT BLOCK
// ENTER BLOCK
lock(mutex){
while(!predicate_for_access):
wait(mutex, conditional_variable)
update predicate for access
}
//EXIT BLOCK
lock(mutex){
update predicate for stopping access
signal/broadcast depending on predicate
}Common bugs with mutexs and how to avoid them
- Use clear names for mutexs and conditional variables so you know what they refer too.
- Check you are locking and unlocking when accessing the resource.
- Check you have matched lock and unlock blocks when using the proxy pattern.
- Remember to use a single mutex for a single resource.
- Check the conditions for signalling and broadcasting.
- Check you are not using signal when you need to use broadcast.
- The other-way around is not an issue for correctness just efficiency as it will wake up the thread and should still execute correctly.
- If you use signal the other threads may never wake up.
- Do you need execution order guarantees?
- Waking up threads does not guarantee this.
- Spurious wakeups
- Deadlocks
Spurious wakeups
Spurious wakeups
Link to originalSpurious wakeups
When waking up threads in a mutex block using signal/broadcast lf you still hold the mutex then the threads will just be moved to waiting on the mutex as it is still held. This is a spurious wakeup as we pay the cost of context switching to the thread just to hand back control to the CPU.
This can sometimes be mitigated by moving the signal/broadcast out of the mutex block.
// WRITE RESOURCE WITH SPURIOUS WAKEUP
lock(mutex){
resource_counter = 0
broadcast(read_phase)
signal(write_phase)
}
// WRITE RSOURCE WITHOUT SPURIOUS WAKEUP
lock(mutex){
resource_counter = 0
}
broadcast(read_phase)
signal(write_phase)Though this can only be done if the signal/broadcast does not rely on a controlled resource like the resource counter in the above example.
Deadlocks
Deadlock
Link to originalDeadlock
There are a couple techniques for solving or preventing deadlocks:
- Fine-grain locking: Forcing threads to only hold one mutex at a time
- This is very limiting to what locks can be used for.
- Composite mutex that combine access to multiple mutex.
- This can be hard to implement and enforce across a wide code base.
- Mutex ordering: You have to obtain mutex in a given order.
- This is the most common solution.
- You have to enforce this order which can be complicated in a large code base.
- Rollback: Detect when deadlocks occur and rollback one of the threads to before the deadlock.
- This is very expensive to implement and involves writing code that can be rolled back.
- You can not use external code that can not be rolled back.
- Ostrich technique: Hope it does not happen and if it does restart the system.
- Terrible to do but very easy to implement.
Thread level
The concept of the thread exists at the kernel level and at the process level that can have its own thread scheduler. Then it is up to the process how it wants to map the threads within the process to threads on the kernel. Threads on the kernel are allocated to the CPU so to get use parallelism whereas multiple process threads on the same kernel thread run concurrently but not in parallel.
Process threads that are directly mapped to kernel threads (bound threads) allows the OS to fully understand that threads requirements and in tern use all the OS features such as synchronisation, blocks, prioritisation directly. This also gives that whole process thread the priority of one system thread. Though this means all operations must go through the OS which can be slow. You have to use the OS thread scheduler meaning less control. Limited by the system you are on such as max thread count, or thread policies which can make your application less portable.
Process threads sharing the same kernel thread have their scheduling controlled by the processes thread manager (unbound threads). This means a lot more control for the process on how to schedule thous threads. Less reliance on the OS features making it more portable. Less OS calls which can speed up applications. Though this means if any of the process threads block the kernel thread then all threads are blocked. The OS is not aware of what the process is doing and can not prioritise that thread using its normal polices.
You can also take a hybrid approach that gets the best of both worlds but requires coordination between the kernel thread scheduler and the process scheduler.
Multi-threading patterns
Boss-worker pattern
In this pattern there is one thread in control of allocating work to a pool of workers. The throughput is determined by the number of tasks the boss processes. There are two main ways for the boss to allocate work to the workers:
- The boss keeps track of which workers are free and allocates new work to free workers. This gives more tasks to the boss as they need to track which workers are free as well as requires a shared interface between the workers and boss to indicate they are free.
- There is a work queue that the boss allocates tasks to once they have processed them. This decouples the worker from the boss but means workers have to synchronise when accessing work from the list. The boss will also have to manage the list when it is full.
An important decision when using this pattern is to decide on the number of workers. This can be done statically up front or dynamically based on the number of tasks through a pool of workers. Most approaches use a hybrid of approaches.
A downside to this model is if the boss is not tracking what workers are doing it can not make efficiencies from specialisations of workers on particular tasks. We can get around this by having workers specialise the tasks they perform which should make them more efficient but means the boss needs to keep track of which workers are specialised to do what and to load balance between them.
Pipeline pattern
In this pattern we break down the task into sub-tasks. Then we let a subset of workers handle each stage of the pipeline. This allows workers to specialise speeding up throughput. Though this means something will have to re-balance worker allocation to the different stages of the pipeline. To hand off workers from one another we require synchronisation of the workers or to pass tasks to a queue.
Layer pattern
In this pattern we group similar sub-tasks and assign them to a layer. Then layers pass tasks between them. This allows for specialisation but reduces the level of fine grained control between each sub-task. Though this suffers from synchronisation between the layers and might not be applicable to all situations.