Week 2 - Regression and classification
Regression history
Regression problems
Link to originalRegression problems
Regression problems are a subset of supervised learning problems where the codomain
is infinite.
The name comes from regression to the mean, this was the technique they used to first talk about it - then the word regression for the technique stuck.
Polynomial Regression
Polynomial regression
Link to originalPolynomial regression
In the modelling framework saying we are doing polynomial regression is saying that we are picking the modelling paradigm of functions of the form
where
, , and we say
is the degree of our polynomial. If
was 1-dimensional this would be:
Once we have an objective function we can use training data to fit the parameters
Note that linear regression is polynomial regression but where
Linear regression
Link to originalLinear regression
Linear regression is the special case of polynomial regression where the degree of the polynomial is 1. Therefore we are restricted to the modelling paradigm of
where . Whilst the may seem more restrictive than polynomial regression with a mutation of the input space linear regression is just as flexible.
Polynomial regression using MSE
Mean squared error (MSE)
Link to originalMean Squared Error (MSE)
The mean squared error is the square of the
norm for two points in , i.e. This is normally applied in the context of machine learning to assess models against some testing data . In the modelling framework we would say the
Calculate polynomial regression coefficients for MSE
Calculate polynomial regression coefficients for MSE
To demonstrate the calculation of the coefficients for polynomial regression with MSE suppose we have 1-dimensional input
and training data . For an order polynomial we are looking for coefficients for that roughly do the following in a completely not mathematically sound way we can do the following rearrangement
completing our fuzzy maths. We use this as our definition of
Link to originaland moreover this has some nice properties that actually minimises with respect to MSE. This can expand out to be multi-variate by increasing the size of and respectively.
Picking a degree
Below is an example of polynomial regression done on different degree polynomials.
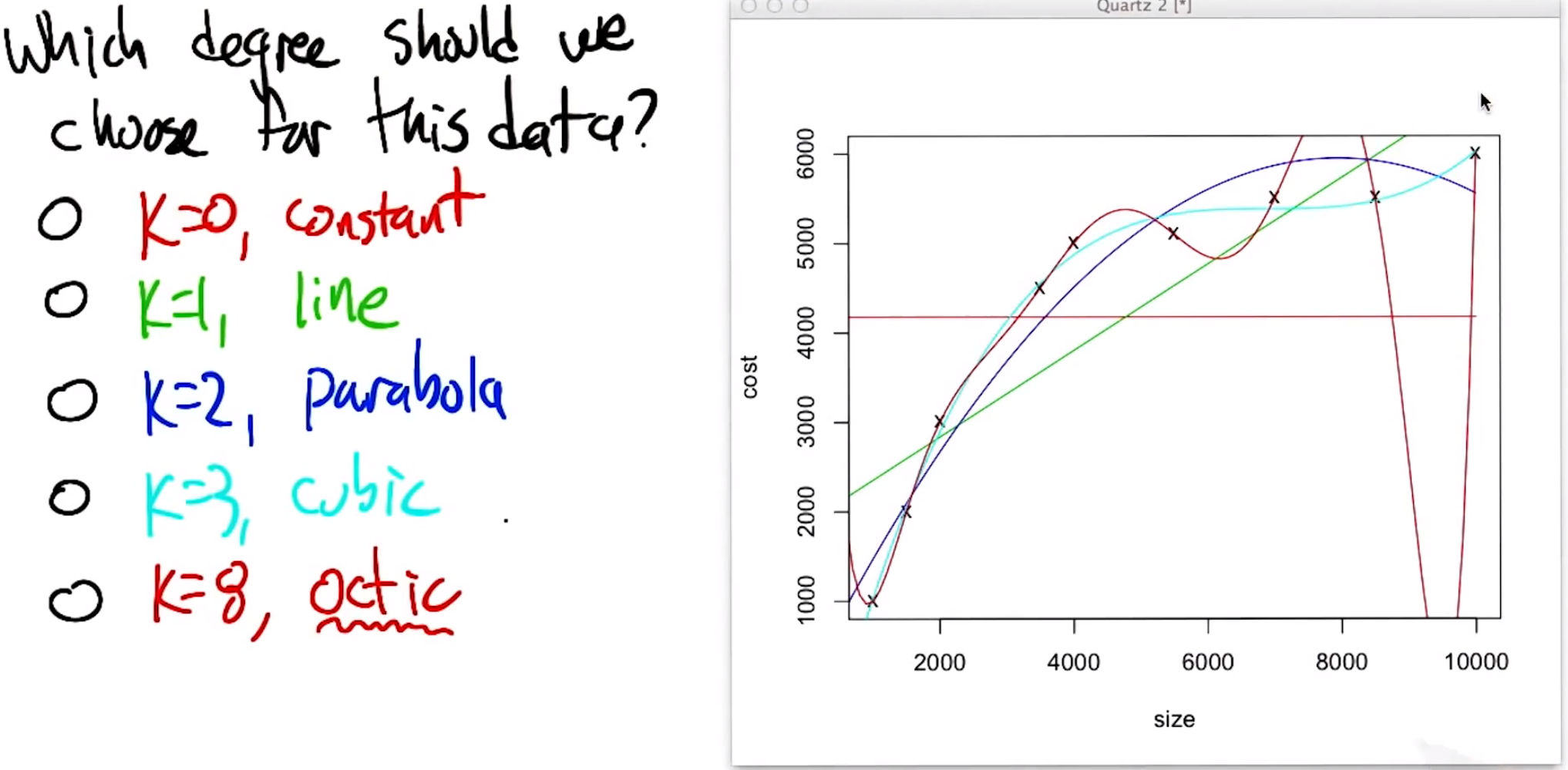
As we increase the degree the fitting polynomial, the fit to the points we are training on gets better. However, at a point the utility of the curve outside of these points gets less.
This is easy to see by eye but how can we computationally infer this?
Cross validation
Cross validation
Link to originalCross validation
Suppose we are training a model on some training data
. If we partition into folds for . Then cross validation is the practice of training the model on all but one fold then assessing it on using our objective function. The practice usually involves doing this for all possible folds and picking the model with least error.
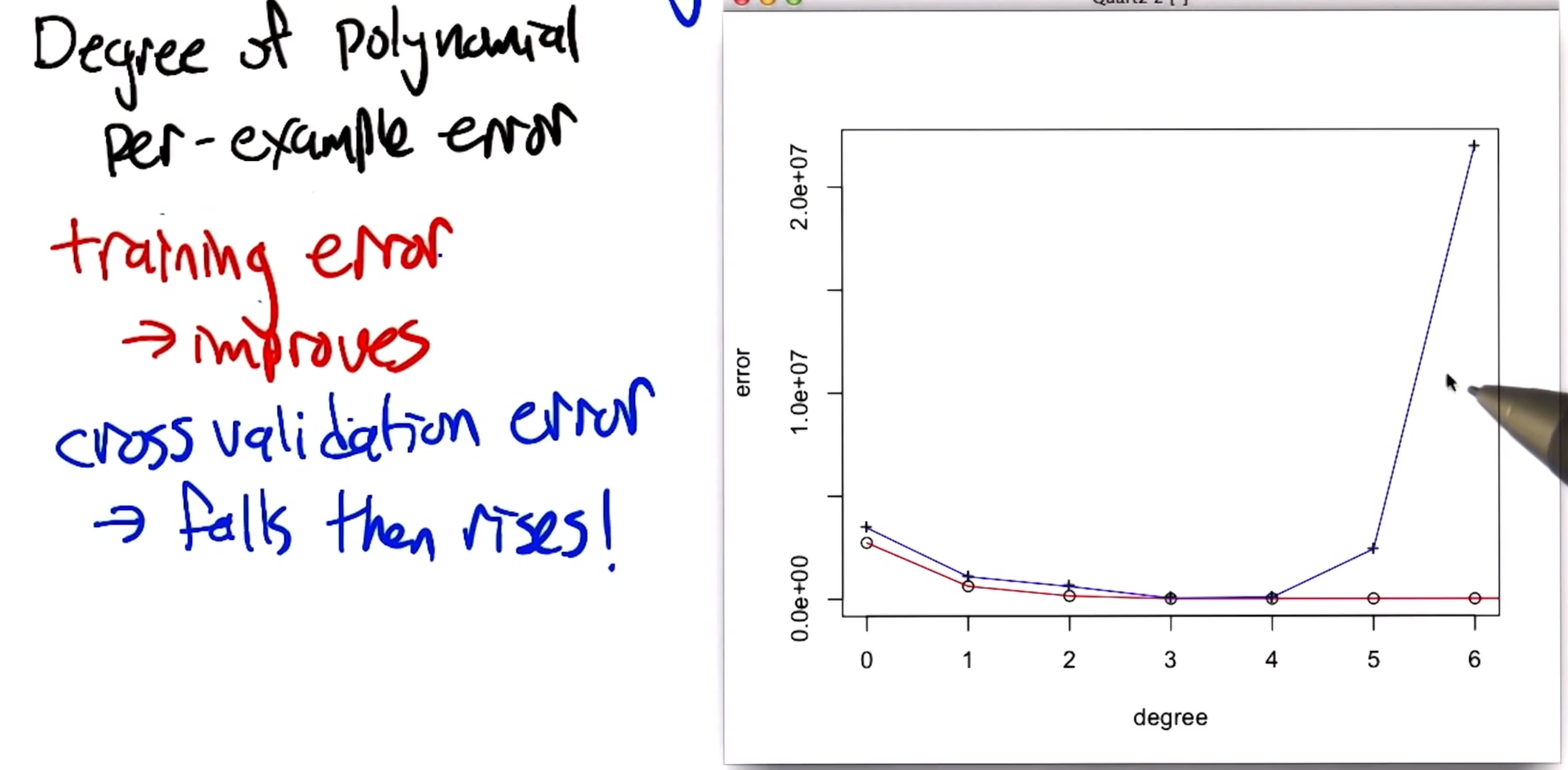
When using cross validation to assess the accuracy of our fit in the example before, you can see it agrees with our intuition. Whilst the high order approximations are a closer fit for the training data, they are a worse fit for the test data. Therefore we could use cross validation to pick the best polynomial without breaking the integrity of the testing data.
Generally you need to find the right sweet spot between underfitting and overfitting by varying the degree of the polynomial.
Getting the right fit
⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠
Text Elements
Underfit
Overfit
Degree
Error
Cross validation error
Test data error
fit
Link to original
Transforming discrete input for regression
Transforming discrete input for regression
Suppose we are in the modelling framework and have been given a discrete input variable
for a regression problem. If has possible values we introduce dimensional space . Then we define the transformation where are the basis vectors of . We would then replace
by in the input space . In the case of boolean input variables, this is as simple as saying
is for False and is for True. You may wonder why no expand this to an
Link to original-dimensional space. This would ruin independence of the variables, as we would know that always these values in these dimensional spaces have to add to 1 - this causes instability in our polynomial regression.